Pickles vs Deep Voice 3
When comparing Pickles vs Deep Voice 3, which AI Text to Speech (TTS) tool shines brighter? We look at pricing, alternatives, upvotes, features, reviews, and more.
Between Pickles and Deep Voice 3, which one is superior?
When we put Pickles and Deep Voice 3 side by side, both being AI-powered text to speech (tts) tools, Both tools have received the same number of upvotes from aitools.fyi users. The power is in your hands! Cast your vote and have a say in deciding the winner.
Think we got it wrong? Cast your vote and show us who's boss!
Pickles
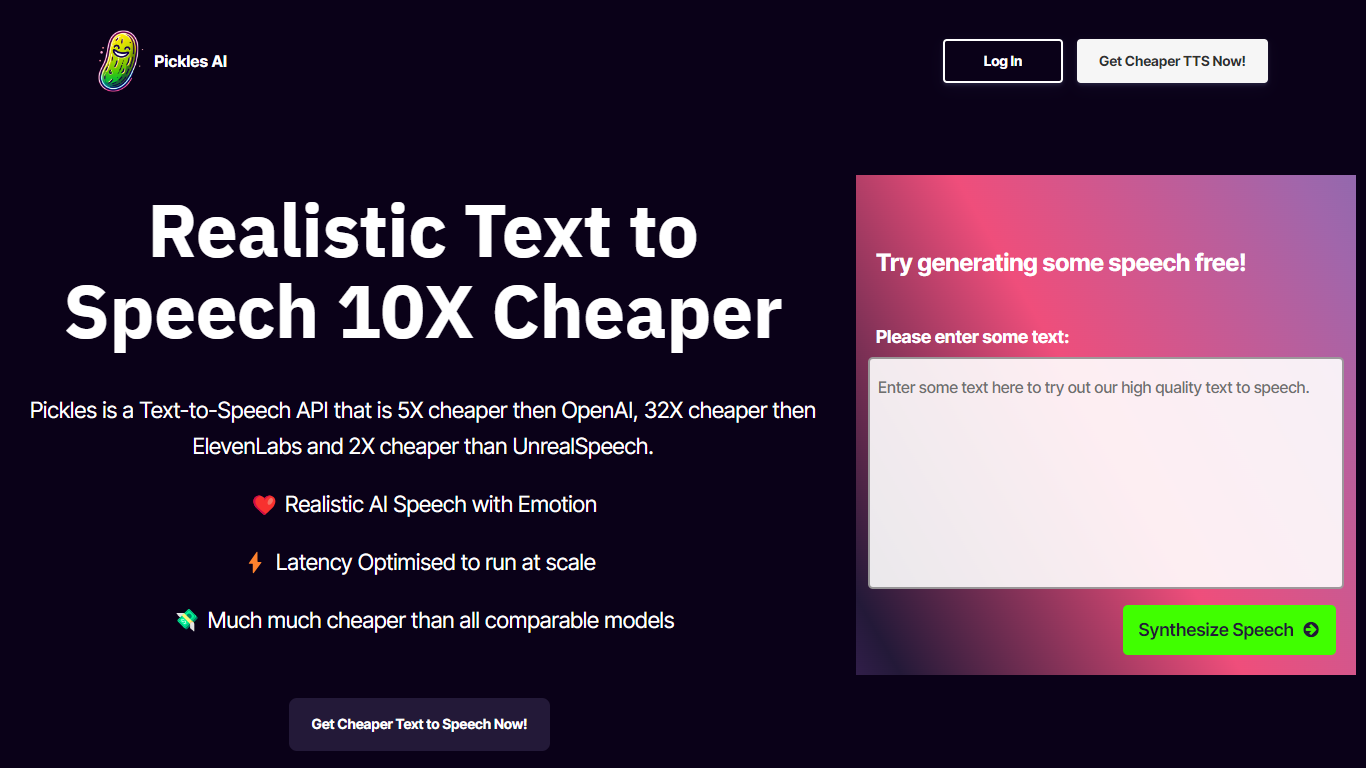

What is Pickles?
Pickles AI offers a groundbreaking Text-to-Speech (TTS) API designed to provide high-quality, realistic AI speech with emotion, while being significantly more cost-effective than competitors.
It boasts a latency optimized performance of approximately 500ms, ensuring swift responses ideal for scaling applications. The TTS service from Pickles stands out not just for being up to 32 times cheaper than rivals like ElevenLabs but also due to its seamless integration that requires only a straightforward HTTPS call.
Interested users and developers can subscribe to get their API key and choose from flexible plans based on their needs, starting from hobby level to enterprise scale. With a promise of no waitlists and a simple sign-up, Pickles AI is making powerful and emotional speech accessible to a wider audience.
Deep Voice 3
What is Deep Voice 3?
Deep Voice 3 is an open source text-to-speech system that uses a fully convolutional neural network to convert text into natural-sounding speech. It supports both single-speaker and multi-speaker models, allowing it to generate speech in various voices and accents. The system is designed to scale efficiently, handling large datasets and training quickly compared to traditional TTS models.
The architecture includes an encoder that processes text inputs, an attention-based decoder that predicts mel-scale spectrograms, and a converter network that generates vocoder parameters for waveform synthesis. This design helps produce clear and natural speech with fewer mispronunciations. Deep Voice 3 also supports training on phoneme, character, or mixed inputs, which improves pronunciation accuracy.
Recent implementations have demonstrated the model's ability to synthesize speech from multiple speakers with distinct accents and ages, showcasing its versatility. Audio samples from various English accents, including Southern England and Scottish, highlight its adaptability to different speech styles.
Deep Voice 3 is suitable for developers and researchers interested in building scalable, high-quality TTS applications. Its open source nature allows customization and experimentation with different model configurations and datasets.
While the core technology remains consistent with the original design, ongoing community efforts focus on improving training efficiency and expanding multi-speaker capabilities. The system's modular structure facilitates integration with other speech processing tools and vocoders.
Overall, Deep Voice 3 offers a balance of speed, scalability, and speech quality, making it a valuable resource for those working on speech synthesis projects that require flexibility across voices and languages.
For detailed technical insights and implementation guidance, the original research paper and open source repositories provide comprehensive resources.
Pickles Upvotes
Deep Voice 3 Upvotes
Pickles Top Features
Cost Efficiency: Offers a TTS API that's significantly cheaper than competitors.
Realism: Provides realistic AI speech that conveys emotion.
Optimized Latency: Ensures low latency (~500ms) for smooth performance at scale.
Ease of Integration: Designed for simple integration with a single HTTPS call.
Flexible Plans: Accommodates different usage needs with various subscription plans.
Deep Voice 3 Top Features
🎤 Multi-speaker support with varied accents and ages for diverse voices
⚡ Fast training speeds enabling quicker model development
🧩 Flexible input options using phonemes, characters, or both for better pronunciation
🔊 Generates mel-scale spectrograms for high-quality audio synthesis
🔧 Open source codebase allowing customization and integration
Pickles Category
- Text to Speech (TTS)
Deep Voice 3 Category
- Text to Speech (TTS)
Pickles Pricing Type
- Freemium
Deep Voice 3 Pricing Type
- Freemium