Deep Voice 3 vs TTSMaker
En el enfrentamiento entre Deep Voice 3 vs TTSMaker, ¿cuál herramienta AI Text to Speech (TTS) se lleva la corona? Escrutamos características, alternativas, votos positivos, opiniones, precios, y más.
Cuando ponemos a Deep Voice 3 y TTSMaker cara a cara, ¿cuál emerge como el vencedor?
Si analizáramos Deep Voice 3 y TTSMaker, ambas herramientas son impulsadas por inteligencia artificial en la categoría de text to speech (tts), ¿qué encontraríamos? El conteo de votos positivos revela un empate, con ambas herramientas obteniendo la misma cantidad de votos positivos. Sé parte del proceso de toma de decisiones. Tu voto podría determinar al ganador.
¿El resultado te hace pensar "mmm"? ¡Emite tu voto y cambia esa expresión!
Deep Voice 3

¿Qué es Deep Voice 3?
Deep Voice 3 es una implementación de código abierto en PyTorch del modelo de texto a voz Deep Voice 3 de Baidu Research. Reproduce el aprendizaje de secuencias convolucionales para TTS neuronal escalable y ofrece puntos de control preentrenados con demos de audio para configuraciones de un solo hablante y de múltiples hablantes.
El proyecto incluye modelos entrenados en LJSpeech para síntesis de un solo hablante y en VCTK para generación multihablante con 108 hablantes. La página de demostración aloja clips de audio de muestra, gráficos de atención y enlaces a pesos preentrenados en GitHub.
Está dirigido a investigadores y desarrolladores que desean una implementación de referencia de Deep Voice 3 en lugar de una API de voz alojada. Los scripts de entrenamiento, el código de inferencia y las contribuciones de la comunidad están en el repositorio público de GitHub.
TTSMaker
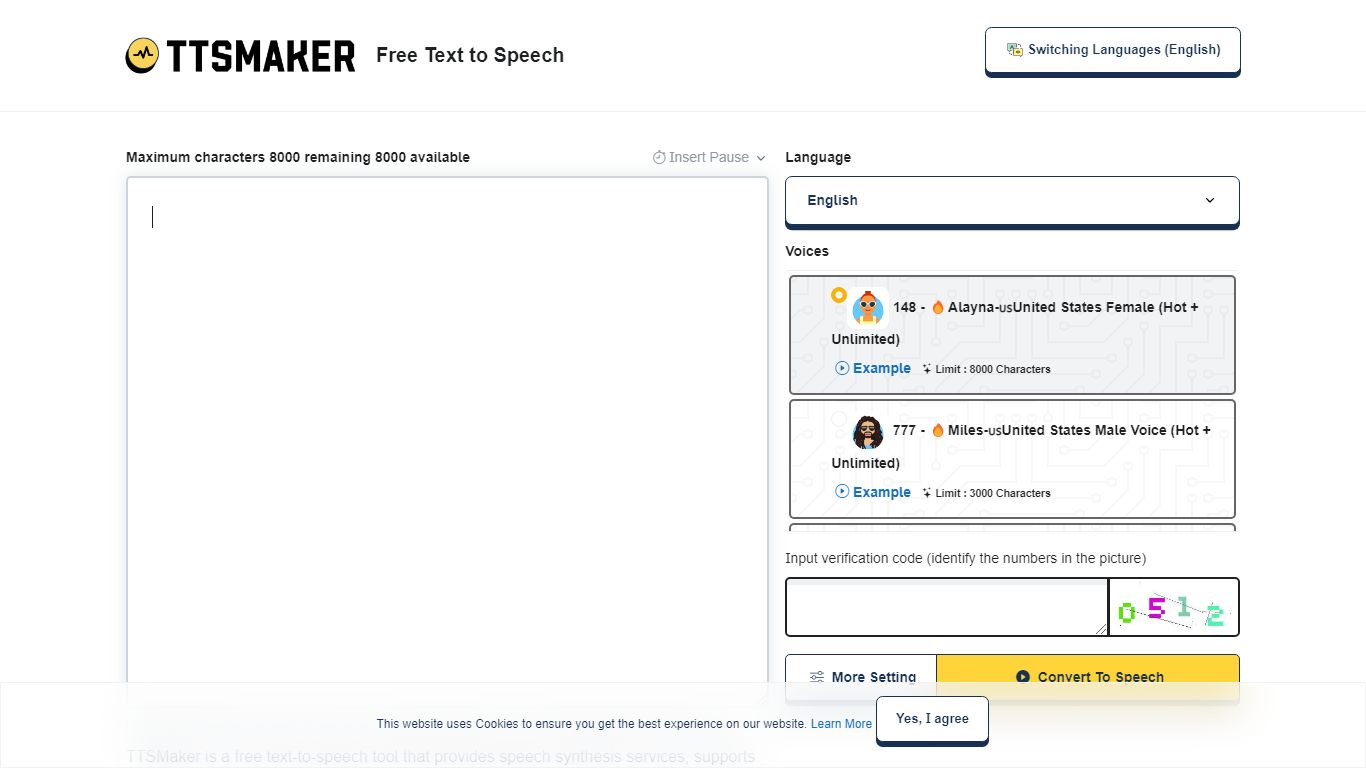
¿Qué es TTSMaker?
TTSMaker es una herramienta gratuita en línea de texto a voz que convierte texto escrito en archivos de audio descargables. Admite más de 100 idiomas y más de 600 voces de inteligencia artificial, por lo que los creadores pueden generar locuciones sin necesidad de contratar actores de voz o grabarse a sí mismos.
La herramienta funciona directamente en tu navegador. Pega el texto, elige un idioma y una voz, ajusta la velocidad, el volumen y el tono, y luego exporta el audio en MP3, OGG, AAC, OPUS o WAV. Un generador de diálogos con múltiples locutores te permite crear conversaciones entre diferentes bloques de voz, cada uno con sus propias configuraciones de idioma y voz.
TTSMaker otorga derechos completos de uso comercial para el audio generado en el plan gratuito, sin necesidad de atribución. Las versiones de pago de TTSMaker Pro ofrecen límites de caracteres más altos, controles de emoción, acceso a API y un editor de diálogos con guardado en la nube de proyectos.
Creadores en YouTube y TikTok, educadores que elaboran materiales de escucha, marketers que producen voces para anuncios y desarrolladores que integran TTS mediante API en planes Pro o Studio son los principales usuarios.
Deep Voice 3 Votos positivos
TTSMaker Votos positivos
Deep Voice 3 Características principales
Implementación en PyTorch de Deep Voice 3, TTS secuencial convolucional
Modelo preentrenado para un solo hablante entrenado con LJSpeech y muestras de audio públicas
Modelo VCTK multi-hablante que soporta 108 hablantes con clips de demostración
Código open-source y checkpoints preentrenados en GitHub
Página de demostración con visualizaciones de atención y enlaces al artículo de referencia
TTSMaker Características principales
Más de 600 voces de IA en más de 100 idiomas, desde inglés estadounidense hasta hindi y japonés
Derechos completos de uso comercial en el plan gratuito sin necesidad de atribución
Exporta audio en MP3, WAV, OGG, AAC o OPUS con velocidad y tono ajustables
Generador de diálogos con múltiples locutores para conversaciones con diferentes voces por bloque
Exportación de subtítulos SRT y mezcla de música de fondo incorporadas en el convertidor
Deep Voice 3 Categoría
- Text to Speech (TTS)
TTSMaker Categoría
- Text to Speech (TTS)
Deep Voice 3 Tipo de tarificación
- Free
TTSMaker Tipo de tarificación
- Freemium