Deep Voice 3 vs Unreal Speech
Al comparar Deep Voice 3 vs Unreal Speech, ¿cuál herramienta AI Text to Speech (TTS) brilla con más intensidad? Examinamos precios, alternativas, votos positivos, características, opiniones, y más.
Entre Deep Voice 3 y Unreal Speech, ¿cuál es superior?
Cuando ponemos Deep Voice 3 y Unreal Speech uno al lado del otro, ambas siendo herramientas impulsadas por inteligencia artificial en la categoría de text to speech (tts), Unreal Speech es el claro ganador en términos de votos positivos. Unreal Speech ha sido votado positivamente 9 veces por usuarios de aitools.fyi, y Deep Voice 3 ha sido votado positivamente 6 veces.
¿Quieres cambiar la historia? ¡Vota por tu herramienta favorita y cambia el juego!
Deep Voice 3

¿Qué es Deep Voice 3?
Deep Voice 3 es un sistema de texto a voz de código abierto que utiliza una red neuronal convolucional completa para convertir texto en un habla de sonido natural. Soporta modelos de un solo hablante y de múltiples hablantes, lo que le permite generar voces en diferentes tonos y acentos. El sistema está diseñado para escalar eficientemente, manejando grandes conjuntos de datos y entrenando rápidamente en comparación con los modelos TTS tradicionales.
La arquitectura incluye un codificador que procesa las entradas de texto, un decodificador basado en atención que predice espectrogramas en escala mel, y una red conversora que genera parámetros para el vocoder para la síntesis de la forma de onda. Este diseño ayuda a producir un habla claro y natural con menos errores de pronunciación. Deep Voice 3 también soporta entrenamiento con entradas de fonemas, caracteres o una mezcla de ambos, lo que mejora la exactitud en la pronunciación.
Implementaciones recientes han demostrado la capacidad del modelo para sintetizar habla de múltiples hablantes con acentos y edades distintas, mostrando su versatilidad. Las muestras de audio de diversos acentos en inglés, incluido el sur de Inglaterra y escocés, resaltan su adaptabilidad a diferentes estilos de habla.
Deep Voice 3 es apto para desarrolladores e investigadores interesados en construir aplicaciones TTS escalables y de alta calidad. Su naturaleza de código abierto permite la personalización y experimentación con diferentes configuraciones de modelos y conjuntos de datos.
Aunque la tecnología central permanece consistente con el diseño original, los esfuerzos comunitarios en curso se enfocan en mejorar la eficiencia del entrenamiento y en ampliar las capacidades de múltiples hablantes. La estructura modular del sistema facilita su integración con otras herramientas de procesamiento de voz y vocoders.
En general, Deep Voice 3 ofrece un equilibrio entre velocidad, escalabilidad y calidad de voz, siendo un recurso valioso para quienes trabajan en proyectos de síntesis de voz que requieren flexibilidad en voces e idiomas.
Para obtener detalles técnicos y orientación de implementación, el artículo de investigación original y los repositorios de código abierto proporcionan recursos detallados.
Unreal Speech
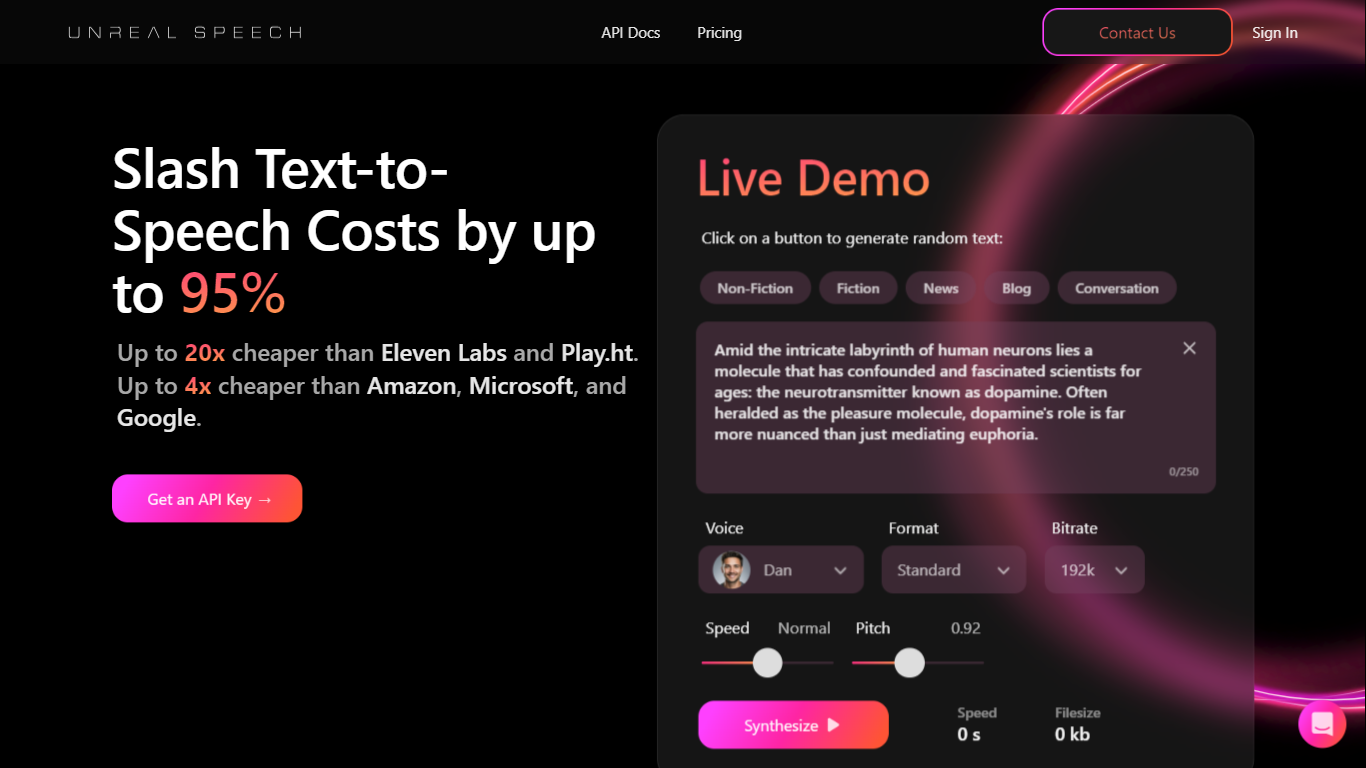
¿Qué es Unreal Speech?
Unreal Speech es una API de texto a voz lista para producción, construida sobre el motor TTS de código abierto Kokoro. Ofrece a desarrolladores y empresas una síntesis de voz natural a una fracción del costo de ElevenLabs, Amazon Polly, Google Cloud y Microsoft Azure. La API transmite audio en aproximadamente 300 milisegundos y soporta trabajos de formato largo de hasta 10 horas por solicitud.
Kokoro funciona con un modelo decodificador de 82 millones de parámetros que combina ideas de StyleTTS 2 e iSTFTNet. Cuenta con 48 voces en ocho idiomas, incluyendo inglés de EE. UU. y del Reino Unido, mandarín, hindi, español, portugués, japonés, francés e italiano. Los marcas de tiempo por palabra permiten que las aplicaciones destaquen el texto sincronizado con la reproducción, lo cual ayuda en accesibilidad, interfaces tipo karaoke y lectores interactivos.
La API REST expone cuatro endpoints: /stream para síntesis subsegundos de hasta 1,000 caracteres, /speech para hasta 3,000 caracteres con URLs de marcas de tiempo, /synthesisTasks para trabajos asincrónicos de hasta 500,000 caracteres y una ruta websocket /streamWithTimestamps para audio en vivo más temporización de palabras. Se ofrecen SDKs para Python, Node.js y React Native, con código de ejemplo en la página principal.
Kokoro TTS Studio en unrealspeech.com ofrece una demo gratuita en navegador para probar las voces antes de registrarse. Los planes de pago eliminan los requisitos de atribución para audio comercial. Clientes empresariales en la plataforma procesan miles de millones de caracteres mensualmente con un tiempo de actividad del 99.9%.
Deep Voice 3 Votos positivos
Unreal Speech Votos positivos
Deep Voice 3 Características principales
🎤 Soporte para múltiples hablantes con acentos y edades variadas para voces diversas
⚡ Velocidades de entrenamiento rápidas que permiten un desarrollo más ágil del modelo
🧩 Opciones de entrada flexibles utilizando fonemas, caracteres o ambos para una mejor pronunciación
🔊 Genera espectrogramas en escala mel para una síntesis de audio de alta calidad
🔧 Código fuente abierto que permite la personalización e integración
Unreal Speech Características principales
Transmite hasta 1,000 caracteres en aproximadamente 300 ms mediante /stream
Las tareas de síntesis asíncronas manejan hasta 500,000 caracteres por solicitud
Las marcas de tiempo por palabra sincronizan la resaltación del texto con la salida de audio
48 voces en ocho idiomas con controles de velocidad y tono
Websocket /streamWithTimestamps ofrece audio en vivo más datos de sincronización
Los SDKs de Python, Node.js y React Native incluyen ejemplos de código
Los trabajos de síntesis individuales pueden producir hasta 10 horas de audio
Deep Voice 3 Categoría
- Text to Speech (TTS)
Unreal Speech Categoría
- Text to Speech (TTS)
Deep Voice 3 Tipo de tarificación
- Freemium
Unreal Speech Tipo de tarificación
- Freemium