Neuralangelo Research Reconstructs 3D Scenes | NVIDIA vs Text-To-4D
En la batalla de Neuralangelo Research Reconstructs 3D Scenes | NVIDIA vs Text-To-4D, ¿cuál herramienta AI 3D Generation sale victoriosa? Comparamos opiniones, precios, alternativas, votos positivos, características, y más.
Entre Neuralangelo Research Reconstructs 3D Scenes | NVIDIA y Text-To-4D, ¿cuál es superior?
Al comparar Neuralangelo Research Reconstructs 3D Scenes | NVIDIA con Text-To-4D, ambas herramientas son impulsadas por inteligencia artificial en la categoría de 3d generation, Con más votos positivos, Text-To-4D es la opción preferida. Text-To-4D ha obtenido 26 votos positivos, y Neuralangelo Research Reconstructs 3D Scenes | NVIDIA ha obtenido 6 votos positivos.
¿Crees que nos equivocamos? ¡Emite tu voto y muéstranos quién manda!
Neuralangelo Research Reconstructs 3D Scenes | NVIDIA

¿Qué es Neuralangelo Research Reconstructs 3D Scenes | NVIDIA?
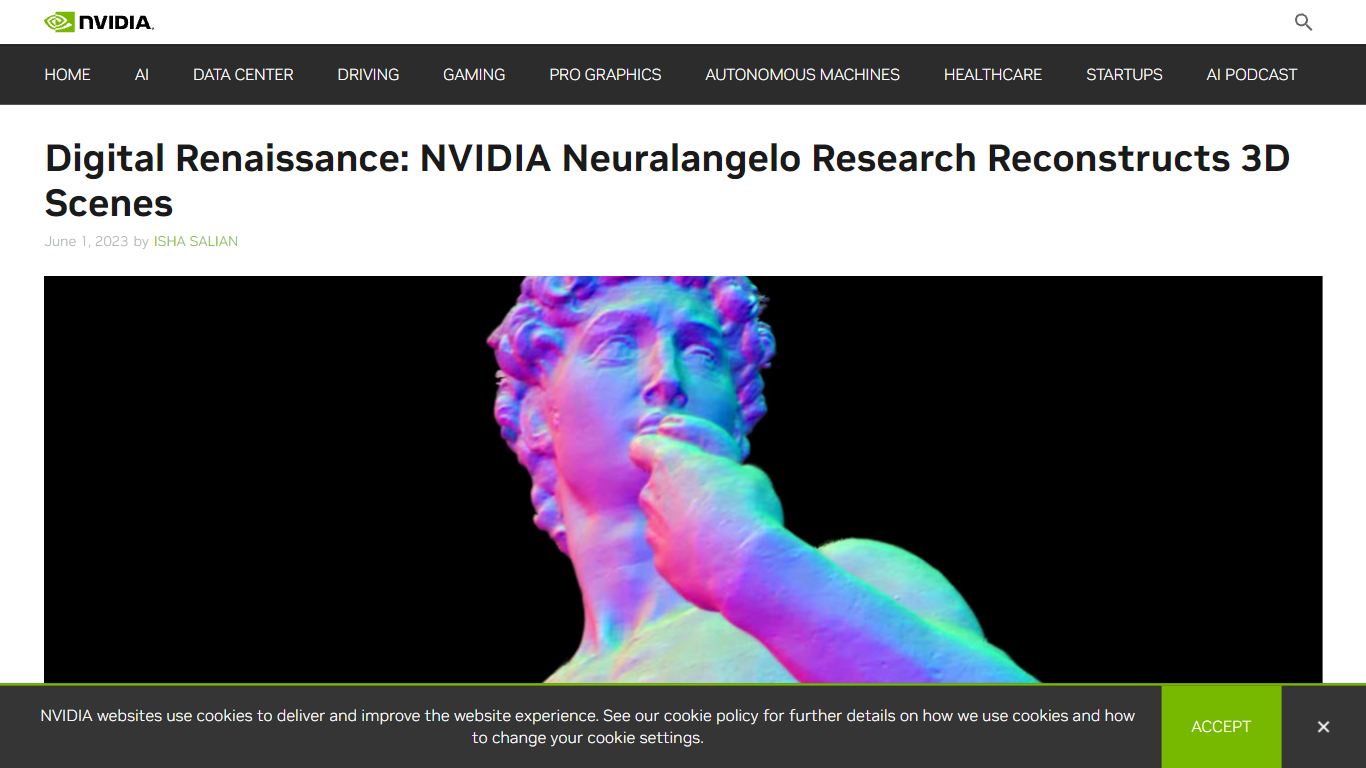
Neuralangelo es un modelo de IA desarrollado por NVIDIA Research que transforma clips de video en 2D en estructuras 3D detalladas mediante redes neuronales. Crea réplicas virtuales realistas de objetos como edificios, esculturas y escenas complejas capturando detalles y texturas intrincadas desde múltiples puntos de vista. Esta tecnología está diseñada para profesionales creativos y desarrolladores que trabajan en realidad virtual, gemelos digitales, robótica y desarrollo de juegos, permitiéndoles importar modelos 3D de alta fidelidad en sus flujos de trabajo de diseño.
A diferencia de métodos anteriores, Neuralangelo sobresale en reproducir materiales complejos como tejas de techo, paneles de vidrio y superficies de mármol lisas con gran precisión. Utiliza primitivas gráficas neuronales instantáneas, la tecnología detrás de NVIDIA Instant NeRF, para captar detalles finos y patrones de textura repetitivos que antes resultaban desafiantes. El modelo procesa fotogramas seleccionados de videos para estimar las posiciones de la cámara y luego construye y perfecciona una representación 3D, similar a un escultor que moldea un sujeto desde múltiples ángulos.
Neuralangelo soporta la reconstrucción tanto de objetos pequeños como de escenas a gran escala, incluyendo interiores y exteriores de edificios, demostrada con modelos detallados como la estatua de David de Michelangelo y el parque del campus de NVIDIA en el Área de la Bahía. Esto lo convierte en una herramienta versátil para industrias que requieren réplicas digitales realistas de entornos y objetos del mundo real.
El modelo simplifica la creación de activos virtuales utilizables a partir de grabaciones incluso realizadas con smartphones, acelerando los flujos de trabajo para artistas, diseñadores y ingenieros. Al cerrar la brecha entre los mundos físico y digital, Neuralangelo mejora el realismo y la eficiencia de proyectos en entretenimiento, diseño industrial y robótica.
NVIDIA ha puesto Neuralangelo disponible en GitHub, fomentando a desarrolladores e investigadores a explorar y construir sobre esta tecnología. Representa un avance significativo en la reconstrucción 3D, combinando renderizado neuronal avanzado con usabilidad práctica para una amplia gama de aplicaciones.
Text-To-4D

¿Qué es Text-To-4D?
Text-To-4D, también conocido como MAV3D (Make-A-Video3D), genera escenas dinámicas tridimensionales a partir de descripciones de texto simples. Utiliza un campo de radiación neural dinámico de 4D (NeRF) optimizado para mantener la apariencia, densidad y movimiento coherentes de la escena, aprovechando un modelo de difusión de Texto-a-Video. Esto permite crear videos dinámicos que pueden ser visualizados desde cualquier ángulo de cámara y integrados en diversos entornos 3D.
A diferencia de los métodos tradicionales de generación 3D, MAV3D no requiere datos de entrenamiento en 3D o 4D. En su lugar, se basa en un modelo de Texto-a-Video entrenado únicamente con pares de texto e imagen y videos no etiquetados, lo que lo hace accesible para usuarios sin conjuntos de datos especializados. Este enfoque abre nuevas posibilidades para creadores, desarrolladores e investigadores interesados en generar contenido dinámico 3D inmersivo a partir de indicaciones de texto.
La herramienta está diseñada para un público amplio, incluyendo desarrolladores de juegos, animadores y creadores de contenido de realidad virtual que desean producir rápidamente escenas dinámicas en 3D sin necesidad de modelado o animación manual. Ofrece un valor único al combinar generación basada en texto con salida de escenas dinámicas en 3D, que puede ser utilizada en aplicaciones interactivas o narrativas visuales.
Desde el punto de vista técnico, el método integra un NeRF de 4D con un modelo de difusión de Texto-a-Video para garantizar la coherencia de movimiento y apariencia a lo largo del tiempo y el espacio. Esto resulta en escenas dinámicas suaves y realistas que pueden ser exploradas desde múltiples puntos de vista. El sistema mejora las bases internas previas al producir videos en 3D de mayor calidad y coherencia a partir de entradas textuales.
En general, Text-To-4D destaca como el primer método conocido para generar escenas 3D completamente dinámicas a partir de texto, cerrando la brecha entre la generación de videos basada en texto y la síntesis de escenas en 3D. Ofrece una solución flexible e innovadora para crear contenido inmersivo sin necesidad de datos complejos en 3D o animación manual.
Neuralangelo Research Reconstructs 3D Scenes | NVIDIA Votos positivos
Text-To-4D Votos positivos
Neuralangelo Research Reconstructs 3D Scenes | NVIDIA Características principales
🎥 Convierte clips de video en 2D en modelos 3D detallados para su fácil uso
🏛️ Captura texturas complejas como vidrio y mármol con alta precisión
🖼️ Soporta la reconstrucción tanto de objetos pequeños como de escenas grandes
📱 Funciona con grabaciones de teléfonos inteligentes, simplificando el proceso de captura
💻 Disponibilidad de código abierto en GitHub para acceso de desarrolladores
Text-To-4D Características principales
🎥 Genera videos 3D dinámicos a partir de indicaciones de texto para una creación de contenido sencilla
🌐 Visualiza escenas generadas desde cualquier ángulo de cámara para explorar ambientes libremente
🛠️ No se requieren datos de entrenamiento 3D o 4D, simplificando el proceso de generación
⚙️ Utiliza un Campo de Radiancia Neural 4D combinado con modelos de difusión para un movimiento suave
🔗 Las salidas pueden integrarse en diversos entornos y aplicaciones 3D
Neuralangelo Research Reconstructs 3D Scenes | NVIDIA Categoría
- 3D Generation
Text-To-4D Categoría
- 3D Generation
Neuralangelo Research Reconstructs 3D Scenes | NVIDIA Tipo de tarificación
- Freemium
Text-To-4D Tipo de tarificación
- Free