Pickles vs Deep Voice 3
Al comparar Pickles vs Deep Voice 3, ¿cuál herramienta AI Text to Speech (TTS) brilla con más intensidad? Examinamos precios, alternativas, votos positivos, características, opiniones, y más.
Entre Pickles y Deep Voice 3, ¿cuál es superior?
Cuando ponemos Pickles y Deep Voice 3 uno al lado del otro, ambas siendo herramientas impulsadas por inteligencia artificial en la categoría de text to speech (tts), Ambas herramientas han recibido la misma cantidad de votos positivos de usuarios de aitools.fyi. ¡El poder está en tus manos! Emite tu voto y participa en la decisión del ganador.
¿Crees que nos equivocamos? ¡Emite tu voto y muéstranos quién manda!
Pickles
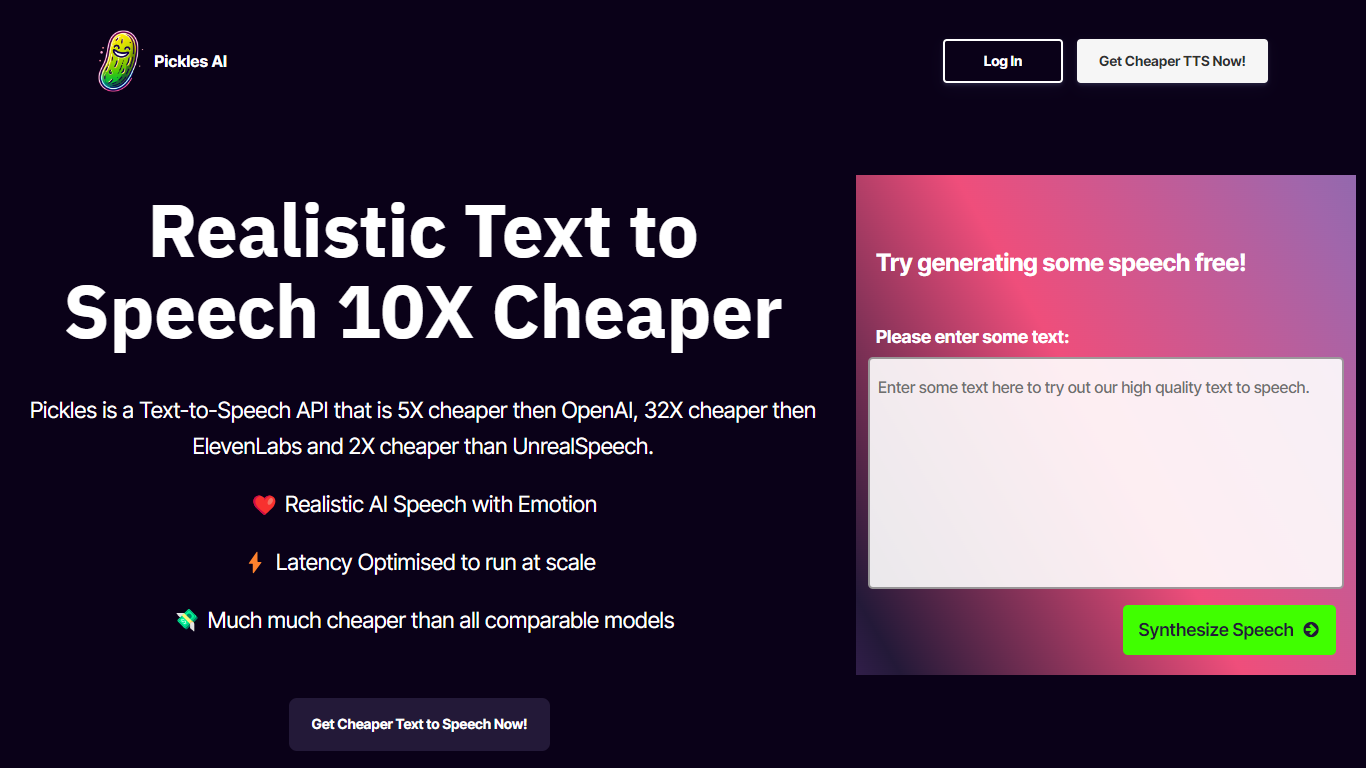

¿Qué es Pickles?
Pickles AI ofrece una innovadora API de texto a voz (TTS) diseñada para proporcionar voz de IA realista y de alta calidad con emoción, al tiempo que es significativamente más rentable que la competencia.
Cuenta con un rendimiento de latencia optimizada de aproximadamente 500 ms, lo que garantiza respuestas rápidas ideales para aplicaciones de escalamiento. El servicio TTS de Pickles destaca no sólo por ser hasta 32 veces más barato que rivales como ElevenLabs, sino también por su perfecta integración que solo requiere una sencilla llamada HTTPS.
Los usuarios y desarrolladores interesados pueden suscribirse para obtener su clave API y elegir entre planes flexibles según sus necesidades, desde el nivel de hobby hasta el de escala empresarial. Con la promesa de no tener listas de espera y con un simple registro, Pickles AI está haciendo que un discurso poderoso y emotivo sea accesible a una audiencia más amplia.
Deep Voice 3
¿Qué es Deep Voice 3?
Deep Voice 3 es un sistema de texto a voz de código abierto que utiliza una red neuronal convolucional completa para convertir texto en un habla de sonido natural. Soporta modelos de un solo hablante y de múltiples hablantes, lo que le permite generar voces en diferentes tonos y acentos. El sistema está diseñado para escalar eficientemente, manejando grandes conjuntos de datos y entrenando rápidamente en comparación con los modelos TTS tradicionales.
La arquitectura incluye un codificador que procesa las entradas de texto, un decodificador basado en atención que predice espectrogramas en escala mel, y una red conversora que genera parámetros para el vocoder para la síntesis de la forma de onda. Este diseño ayuda a producir un habla claro y natural con menos errores de pronunciación. Deep Voice 3 también soporta entrenamiento con entradas de fonemas, caracteres o una mezcla de ambos, lo que mejora la exactitud en la pronunciación.
Implementaciones recientes han demostrado la capacidad del modelo para sintetizar habla de múltiples hablantes con acentos y edades distintas, mostrando su versatilidad. Las muestras de audio de diversos acentos en inglés, incluido el sur de Inglaterra y escocés, resaltan su adaptabilidad a diferentes estilos de habla.
Deep Voice 3 es apto para desarrolladores e investigadores interesados en construir aplicaciones TTS escalables y de alta calidad. Su naturaleza de código abierto permite la personalización y experimentación con diferentes configuraciones de modelos y conjuntos de datos.
Aunque la tecnología central permanece consistente con el diseño original, los esfuerzos comunitarios en curso se enfocan en mejorar la eficiencia del entrenamiento y en ampliar las capacidades de múltiples hablantes. La estructura modular del sistema facilita su integración con otras herramientas de procesamiento de voz y vocoders.
En general, Deep Voice 3 ofrece un equilibrio entre velocidad, escalabilidad y calidad de voz, siendo un recurso valioso para quienes trabajan en proyectos de síntesis de voz que requieren flexibilidad en voces e idiomas.
Para obtener detalles técnicos y orientación de implementación, el artículo de investigación original y los repositorios de código abierto proporcionan recursos detallados.
Pickles Votos positivos
Deep Voice 3 Votos positivos
Pickles Características principales
Eficiencia de costos: Ofrece una API TTS que es significativamente más económica que la de la competencia.
Realismo: Proporciona un discurso realista de IA que transmite emoción.
Latencia optimizada: Garantiza una latencia baja (~500 ms) para un rendimiento fluido a escala.
Facilidad de integración: Diseñado para una integración sencilla con una única llamada HTTPS.
Planes flexibles: Se adapta a diferentes necesidades de uso con varios planes de suscripción.
Deep Voice 3 Características principales
🎤 Soporte para múltiples hablantes con acentos y edades variadas para voces diversas
⚡ Velocidades de entrenamiento rápidas que permiten un desarrollo más ágil del modelo
🧩 Opciones de entrada flexibles utilizando fonemas, caracteres o ambos para una mejor pronunciación
🔊 Genera espectrogramas en escala mel para una síntesis de audio de alta calidad
🔧 Código fuente abierto que permite la personalización e integración
Pickles Categoría
- Text to Speech (TTS)
Deep Voice 3 Categoría
- Text to Speech (TTS)
Pickles Tipo de tarificación
- Freemium
Deep Voice 3 Tipo de tarificación
- Freemium