Unreal Speech vs SpeechGen
En la batalla de Unreal Speech vs SpeechGen, ¿cuál herramienta AI Text to Speech (TTS) sale victoriosa? Comparamos opiniones, precios, alternativas, votos positivos, características, y más.
Entre Unreal Speech y SpeechGen, ¿cuál es superior?
Al comparar Unreal Speech con SpeechGen, ambas herramientas son impulsadas por inteligencia artificial en la categoría de text to speech (tts), Los usuarios han dejado clara su preferencia, Unreal Speech lidera en votos positivos. El número de votos positivos para Unreal Speech es de 9, y para SpeechGen es de 7.
¿El resultado te hace pensar "mmm"? ¡Emite tu voto y cambia esa expresión!
Unreal Speech
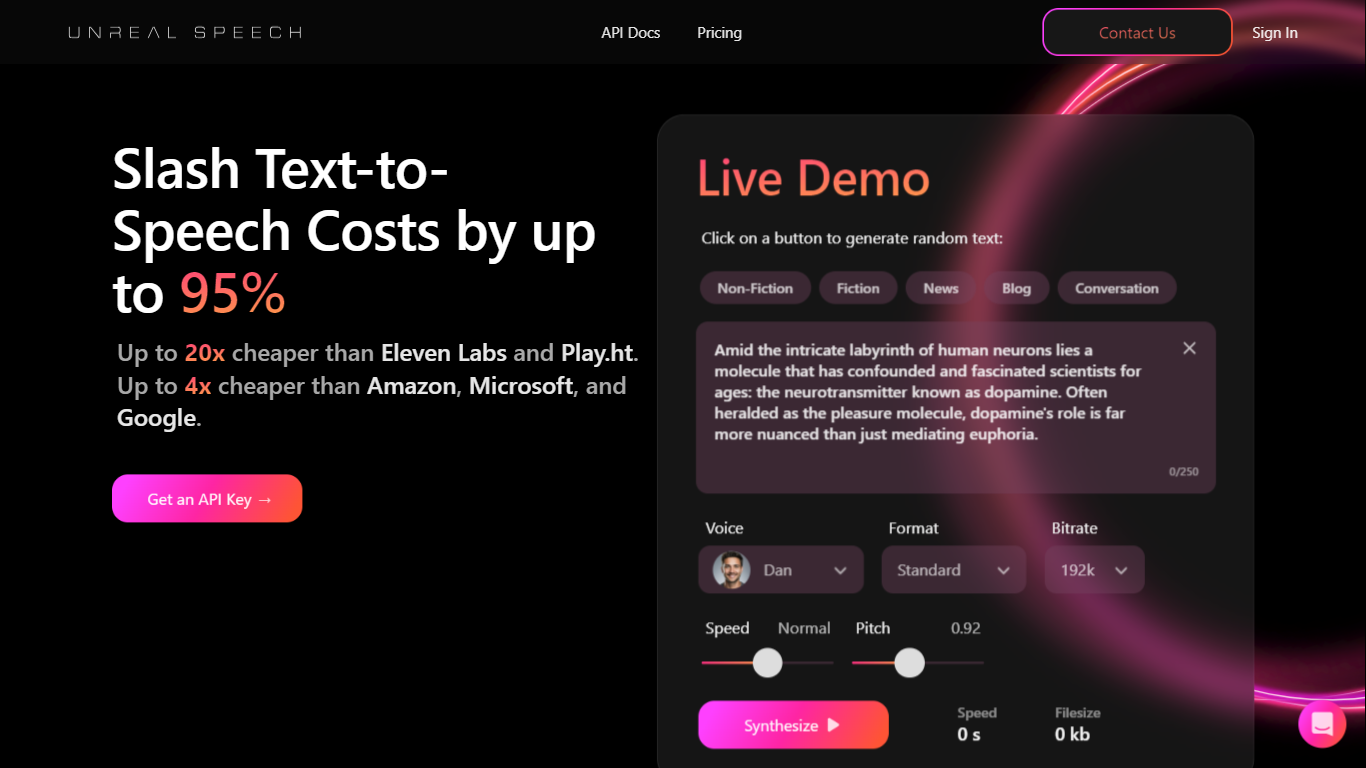

¿Qué es Unreal Speech?
Unreal Speech es una API de texto a voz lista para producción, construida sobre el motor TTS de código abierto Kokoro. Ofrece a desarrolladores y empresas una síntesis de voz natural a una fracción del costo de ElevenLabs, Amazon Polly, Google Cloud y Microsoft Azure. La API transmite audio en aproximadamente 300 milisegundos y soporta trabajos de formato largo de hasta 10 horas por solicitud.
Kokoro funciona con un modelo decodificador de 82 millones de parámetros que combina ideas de StyleTTS 2 e iSTFTNet. Cuenta con 48 voces en ocho idiomas, incluyendo inglés de EE. UU. y del Reino Unido, mandarín, hindi, español, portugués, japonés, francés e italiano. Los marcas de tiempo por palabra permiten que las aplicaciones destaquen el texto sincronizado con la reproducción, lo cual ayuda en accesibilidad, interfaces tipo karaoke y lectores interactivos.
La API REST expone cuatro endpoints: /stream para síntesis subsegundos de hasta 1,000 caracteres, /speech para hasta 3,000 caracteres con URLs de marcas de tiempo, /synthesisTasks para trabajos asincrónicos de hasta 500,000 caracteres y una ruta websocket /streamWithTimestamps para audio en vivo más temporización de palabras. Se ofrecen SDKs para Python, Node.js y React Native, con código de ejemplo en la página principal.
Kokoro TTS Studio en unrealspeech.com ofrece una demo gratuita en navegador para probar las voces antes de registrarse. Los planes de pago eliminan los requisitos de atribución para audio comercial. Clientes empresariales en la plataforma procesan miles de millones de caracteres mensualmente con un tiempo de actividad del 99.9%.
SpeechGen
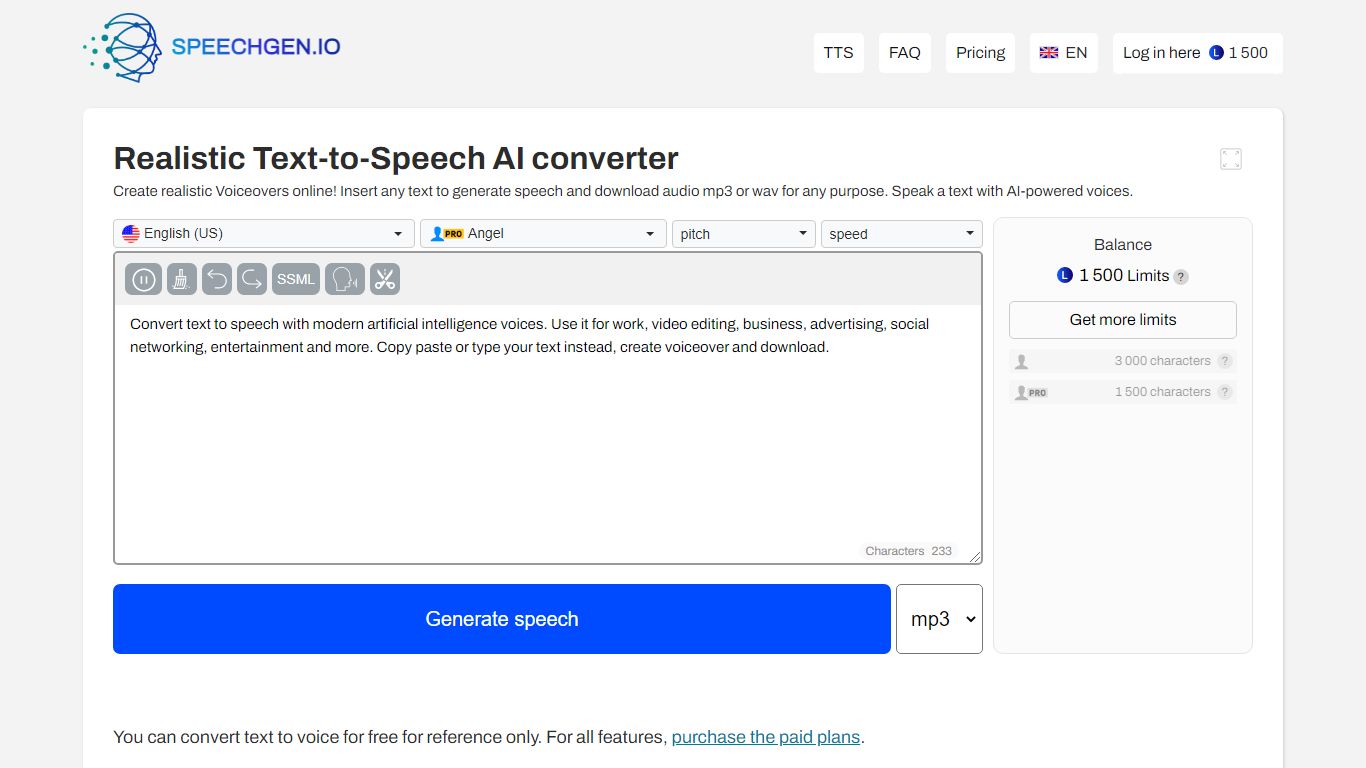
¿Qué es SpeechGen?
SpeechGen es una plataforma de texto a voz impulsada por inteligencia artificial que crea doblajes realistas de manera rápida y asequible. Soporta más de 1,000 voces de sonido natural en 150 idiomas y acentos, incluyendo voces masculinas, femeninas, infantiles y de personas mayores. Los usuarios pueden convertir textos largos—hasta 2 millones de caracteres en una sola solicitud—lo que la hace adecuada para contenidos de forma larga como audiolibros y presentaciones. La plataforma ofrece una tarifa flexible de pago por uso con pagos únicos para límites de síntesis de voz, evitando suscripciones mensuales y permitiendo a los usuarios controlar sus gastos de manera efectiva. SpeechGen soporta uso comercial, permitiendo a los creadores producir audio para redes sociales, podcasts, anuncios y más. Entre sus funciones avanzadas de personalización de voz se incluyen ajustes en la velocidad, tono, énfasis, pronunciación y pausas, con soporte SSML para un control preciso. También convierte subtítulos y documentos en audio, mejorando la accesibilidad y el alcance del contenido. Todos los archivos de audio generados se pueden descargar en múltiples formatos y se almacenan de forma segura en la nube para un fácil acceso y gestión. SpeechGen se integra fácilmente con software popular de edición de video y audio, convirtiéndola en una herramienta versátil para creadores de contenido, educadores, mercadólogos y desarrolladores.
Unreal Speech Votos positivos
SpeechGen Votos positivos
Unreal Speech Características principales
Transmite hasta 1,000 caracteres en aproximadamente 300 ms mediante /stream
Las tareas de síntesis asíncronas manejan hasta 500,000 caracteres por solicitud
Las marcas de tiempo por palabra sincronizan la resaltación del texto con la salida de audio
48 voces en ocho idiomas con controles de velocidad y tono
Websocket /streamWithTimestamps ofrece audio en vivo más datos de sincronización
Los SDKs de Python, Node.js y React Native incluyen ejemplos de código
Los trabajos de síntesis individuales pueden producir hasta 10 horas de audio
SpeechGen Características principales
🎙️ Más de 1,000 voces naturales en 150 idiomas para diversas necesidades
💰 Tarifas de pago por uso con pagos únicos para un gasto flexible
📝 Convierte textos largos de hasta 2 millones de caracteres de una sola vez
⚙️ Personaliza fácilmente la velocidad, tono, énfasis y pronunciación de la voz
📂 Descarga audio en MP3, WAV u OGG y guarda archivos en la nube
Unreal Speech Categoría
- Text to Speech (TTS)
SpeechGen Categoría
- Text to Speech (TTS)
Unreal Speech Tipo de tarificación
- Freemium
SpeechGen Tipo de tarificación
- Paid