
Última actualización 10-31-2025
Categoría:
Reviews:
Join thousands of AI enthusiasts in the World of AI!
WebcrawlerAPI
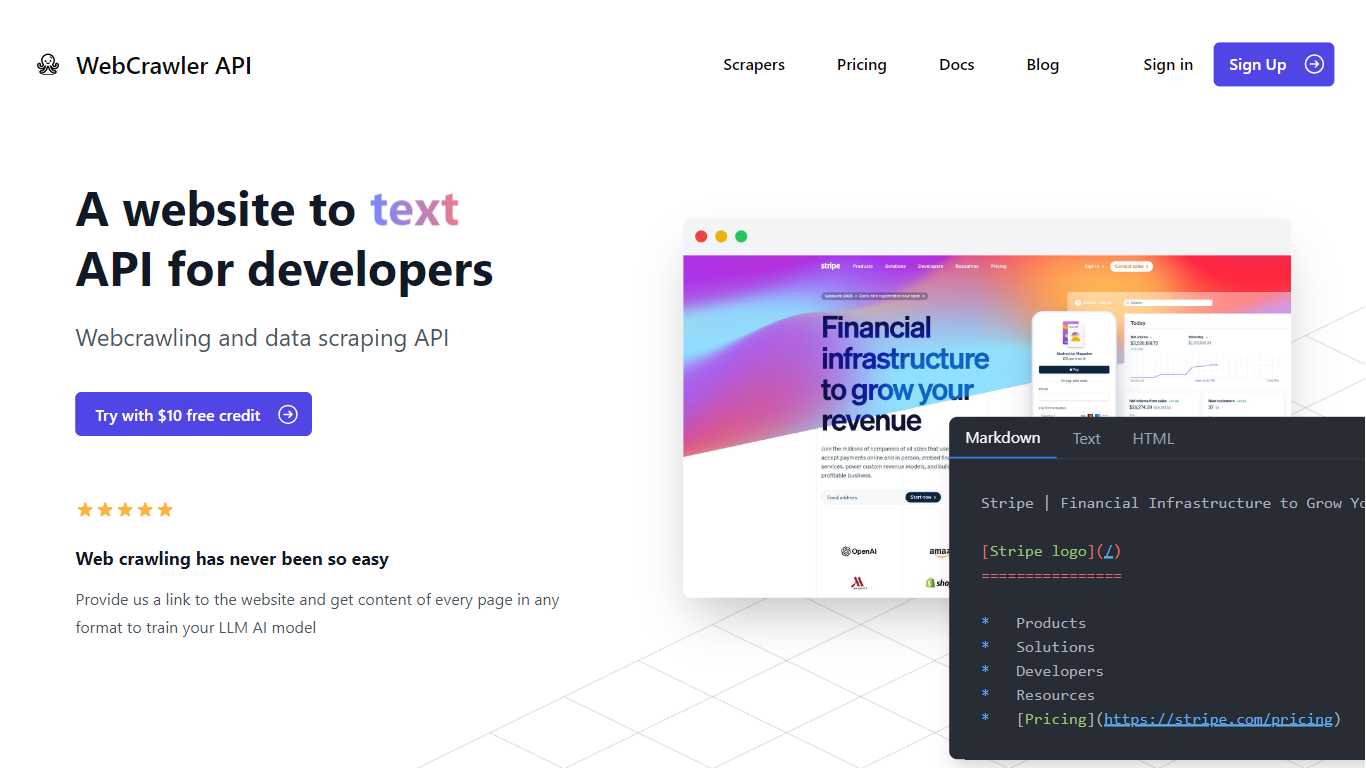
WebcrawlerAPI es un servicio sencillo de rastreo web y extracción de datos diseñado para facilitar la recopilación de contenido de casi cualquier sitio web. Ofrece una llamada a la API simple que devuelve contenido de página limpio y estructurado, formateado para generación aumentada por recuperación (RAG) o contextos de modelos de lenguaje grande (LLM). Esto lo hace ideal para desarrolladores, científicos de datos y empresas que crean aplicaciones de IA o necesitan datos web confiables.
El servicio maneja todos los desafíos técnicos desde segundo plano, incluyendo la gestión de proxies, reintentos, navegadores sin cabeza, CAPTCHAs y protecciones anti-bots. Esto significa que los usuarios no tienen que preocuparse por configuraciones complejas ni por construir rastreadores personalizados. La API se centra en entregar un análisis preciso del contenido, extrayendo el contenido principal en formatos Markdown o texto plano.
WebcrawlerAPI soporta integraciones sin código, permitiendo a los usuarios añadir rastreo web a sus flujos de trabajo rápidamente, sin necesidad de escribir código. Cuenta con una tasa de éxito del 91% y un tiempo promedio de rastreo de aproximadamente 9 segundos, lo que lo hace confiable y eficiente. El modelo de precios es simple y basado en uso, sin suscripciones ni tarifas ocultas.
El soporte es provisto por ingenieros reales, no chatbots, asegurando que los usuarios reciban ayuda práctica cuando la necesiten. La herramienta es especialmente útil para quienes trabajan en sistemas RAG o en entrenamiento de modelos de IA y necesitan contenido web limpio y listo para usar. Su enfoque en la facilidad de integración y en rastreo listo para producción lo diferencia de muchas otras herramientas de scraping.
En resumen, WebcrawlerAPI es una opción práctica para quienes necesitan extracción de datos web escalable y precisa, sin complicaciones de gestionar la infraestructura subyacente o los desafíos anti-bot.
📡 Acceso fácil a la API que entrega contenido web rápidamente
🛠️ Gestiona proxies, reintentos y CAPTCHAs automáticamente
📄 Extrae el contenido principal de la página en Markdown o texto
⚙️ Integraciones sin código para una configuración rápida sin programar
👩💻 Soporte humano real para ayuda con la integración
Maneja desafíos complejos de rastreo como CAPTCHAs y anti-bots automáticamente
Proporciona contenido limpio y estructurado listo para casos de uso de IA y RAG
Soporta integración sin código para una configuración fácil sin programación
Ofrece soporte humano real para una resolución de problemas más rápida
Precios simples de pago por uso sin suscripciones
No se menciona nivel gratuito ni prueba para testar antes de la compra
El tiempo promedio de rastreo alrededor de 9 segundos puede ser más lento que algunos competidores
¿Puedo rastrear páginas específicas o sitios web completos con WebcrawlerAPI?
Sí, WebcrawlerAPI te permite rastrear páginas individuales o sitios web completos proporcionando las URL desde las que deseas extraer contenido.
¿Es WebcrawlerAPI adecuado para construir sistemas de generación aumentada por recuperación (RAG)?
Absolutamente. La API devuelve contenido formateado para contextos RAG o LLM, lo que la hace ideal para aplicaciones de IA que requieren datos web limpios y estructurados.
¿Necesito gestionar proxies o medidas anti-bots al usar WebcrawlerAPI?
No, WebcrawlerAPI maneja proxies, reintentos, navegadores sin interfaz, CAPTCHAs y protecciones anti-bots automáticamente para que no tengas que hacerlo.
¿Puedo integrar WebcrawlerAPI sin escribir código?
Sí, el servicio admite integraciones sin código, lo que te permite agregar rastreo web a tus flujos de trabajo de forma rápida y sencilla.
¿Existe una tarifa de suscripción para usar WebcrawlerAPI?
No, WebcrawlerAPI utiliza un modelo de precios de pago por uso sin suscripciones ni tarifas ocultas.
¿Qué tipo de soporte ofrece WebcrawlerAPI?
Recibes soporte humano real de ingenieros, no chatbots, para ayudarte con la integración y cualquier problema que enfrentes.
¿Qué tan rápido es el proceso de rastreo con WebcrawlerAPI?
En promedio, WebcrawlerAPI completa un rastreo en aproximadamente 9 segundos con una tasa de éxito del 91%.