Neuralangelo Research Reconstructs 3D Scenes | NVIDIA vs Text-To-4D
Dans la bataille de Neuralangelo Research Reconstructs 3D Scenes | NVIDIA vs Text-To-4D, quel outil AI 3D Generation sort en tête? Nous comparons les avis, les prix, les alternatives, les votes positifs, les fonctionnalités, et plus encore.
Entre Neuralangelo Research Reconstructs 3D Scenes | NVIDIA et Text-To-4D, lequel est supérieur?
En comparant Neuralangelo Research Reconstructs 3D Scenes | NVIDIA avec Text-To-4D, qui sont tous deux des outils 3d generation alimentés par l'IA, Avec plus de votes positifs, Text-To-4D est le choix préféré. Text-To-4D a recueilli 26 votes positifs, et Neuralangelo Research Reconstructs 3D Scenes | NVIDIA a recueilli 6 votes positifs.
Vous pensez que nous avons tort? Votez et montrez-nous qui est le patron!
Neuralangelo Research Reconstructs 3D Scenes | NVIDIA

Qu'est-ce que Neuralangelo Research Reconstructs 3D Scenes | NVIDIA?
Neuralangelo est un modèle d'intelligence artificielle développé par NVIDIA Research qui transforme des clips vidéo 2D en structures 3D détaillées en utilisant des réseaux neuronaux. Il crée des répliques virtuelles réalistes d'objets tels que des bâtiments, des sculptures et des scènes complexes en capturant des détails et textures intricats depuis plusieurs points de vue. Cette technologie est conçue pour les professionnels de la création et les développeurs travaillant dans la réalité virtuelle, les jumeaux numériques, la robotique et le développement de jeux, leur permettant d'importer des modèles 3D de haute fidélité dans leurs flux de travail de conception.
Contrairement aux méthodes antérieures, Neuralangelo excelle dans la reproduction de matériaux complexes comme les shingles de toiture, les vitres et les surfaces en marbre lisse avec une grande précision. Il utilise des primitives graphiques neuronales instantanées, la technologie à l'origine de NVIDIA Instant NeRF, pour capturer les détails fins et les motifs de textures répétitifs qui étaient auparavant difficiles à représenter. Le modèle traite des images sélectionnées de vidéos pour estimer les positions de la caméra, puis construit et affinez une représentation 3D, à l'image d'un sculpteur façonnant un sujet depuis plusieurs angles.
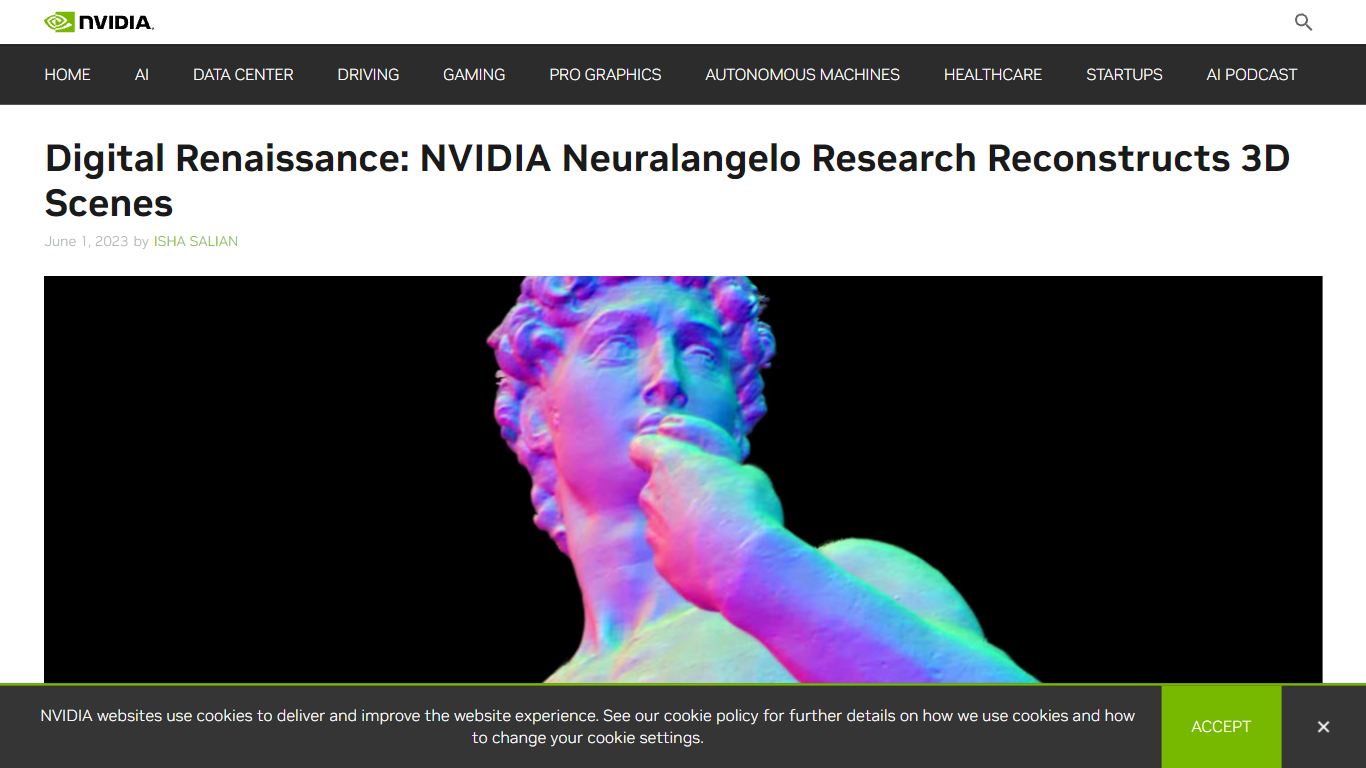
Neuralangelo prend en charge la reconstruction d'objets petits comme de scènes à grande échelle, y compris l'intérieur et l'extérieur de bâtiments, comme le montrent des modèles détaillés tels que la statue de David de Michel-Ange et le parc du campus de NVIDIA à la Baie. Cela en fait un outil polyvalent pour les industries nécessitant des répliques numériques réalistes d'environnements et d'objets du monde réel.
Le modèle simplifie la création d'actifs virtuels utilisables à partir de séquences filmées, même avec un smartphone, accélérant ainsi les flux de travail des artistes, designers et ingénieurs. En comblant le fossé entre le monde physique et numérique, Neuralangelo améliore le réalisme et l'efficacité des projets dans les domaines du divertissement, du design industriel et de la robotique.
NVIDIA a rendu Neuralangelo disponible sur GitHub, encourageant les développeurs et chercheurs à explorer et à construire sur cette technologie. Il représente une avancée significative dans la reconstruction 3D, combinant un rendu neuronal avancé avec une utilité pratique pour une large gamme d'applications.
Text-To-4D

Qu'est-ce que Text-To-4D?
Text-To-4D, également connu sous le nom de MAV3D (Make-A-Video3D), génère des scènes dynamiques tridimensionnelles à partir de descriptions textuelles simples. Il utilise un champ de radiance neuronal dynamique 4D (NeRF) optimisé pour une cohérence dans l'apparence de la scène, la densité et le mouvement en tirant parti d'un modèle de diffusion Text-to-Video. Cela permet de créer des vidéos dynamiques pouvant être visualisées sous n'importe quel angle de caméra et intégrées dans divers environnements 3D.
Contrairement aux méthodes traditionnelles de génération 3D, MAV3D ne requiert aucune donnée d'entraînement 3D ou 4D. Il s'appuie plutôt sur un modèle Text-to-Video entraîné uniquement sur des paires texte-image et des vidéos non étiquetées, le rendant accessible aux utilisateurs ne disposant pas de jeux de données spécialisés. Cette approche ouvre de nouvelles possibilités pour les créateurs, développeurs et chercheurs souhaitant générer du contenu 3D immersif à partir de simples invites textuelles.
L'outil est destiné à un large public, incluant les développeurs de jeux, les animateurs et les créateurs de contenu en réalité virtuelle qui veulent produire rapidement des scènes 3D dynamiques sans modélisation ou animation manuelle. Il offre une valeur unique en combinant la génération basée sur le texte avec la sortie de scènes 3D dynamiques, utilisables dans des applications interactives ou pour la narration visuelle.
Techniquement, la méthode intègre un NeRF 4D avec un modèle de diffusion Text-to-Video pour garantir la cohérence du mouvement et de l'apparence dans le temps et l'espace. Cela aboutit à des scènes dynamiques fluides et réalistes, explorables sous plusieurs points de vue. Le système améliore les précédents benchmarks en produisant des vidéos 3D de meilleure qualité et plus cohérentes à partir d’un texte.
Dans l’ensemble, Text-To-4D se démarque comme la première méthode connue pour générer des scènes 3D entièrement dynamiques à partir de texte, comblant le gap entre la génération vidéo basée sur le texte et la synthèse de scènes 3D. Il offre une solution flexible et innovante pour créer du contenu immersif sans nécessiter de données 3D complexes ou d'animation manuelle.
Neuralangelo Research Reconstructs 3D Scenes | NVIDIA Votes positifs
Text-To-4D Votes positifs
Neuralangelo Research Reconstructs 3D Scenes | NVIDIA Fonctionnalités principales
🎥 Convertit des clips vidéo 2D en modèles 3D détaillés pour une utilisation facile
🏛️ Capture des textures complexes comme le verre et le marbre avec une grande précision
🖼️ Prend en charge la reconstruction aussi bien d'objets petits que de scènes vastes
📱 Fonctionne avec des séquences filmées sur smartphones, simplifiant le processus de capture
💻 Disponible en open-source sur GitHub pour un accès développeur
Text-To-4D Fonctionnalités principales
🎥 Génère des vidéos 3D dynamiques à partir de descriptions textuelles pour une création de contenu simplifiée
🌐 Visualisez les scènes générées depuis n'importe quel angle de caméra pour explorer librement les environnements
🛠️ Aucun besoin de données d'entraînement 3D ou 4D, ce qui simplifie le processus de génération
⚙️ Utilise un champ de radiance neuronal 4D combiné à des modèles de diffusion pour un mouvement fluide
🔗 Les résultats peuvent être intégrés dans divers environnements et applications 3D
Neuralangelo Research Reconstructs 3D Scenes | NVIDIA Catégorie
- 3D Generation
Text-To-4D Catégorie
- 3D Generation
Neuralangelo Research Reconstructs 3D Scenes | NVIDIA Type de tarification
- Freemium
Text-To-4D Type de tarification
- Free