Unreal Speech vs SpeechGen
Dans la bataille de Unreal Speech vs SpeechGen, quel outil AI Text to Speech (TTS) sort en tête? Nous comparons les avis, les prix, les alternatives, les votes positifs, les fonctionnalités, et plus encore.
Entre Unreal Speech et SpeechGen, lequel est supérieur?
En comparant Unreal Speech avec SpeechGen, qui sont tous deux des outils text to speech (tts) alimentés par l'IA, Les utilisateurs ont clairement exprimé leur préférence, Unreal Speech mène en termes de votes positifs. Le nombre de votes positifs pour Unreal Speech est de 9, et pour SpeechGen il est de 7.
Le résultat vous fait dire "hmm"? Votez et transformez cette grimace en sourire!
Unreal Speech
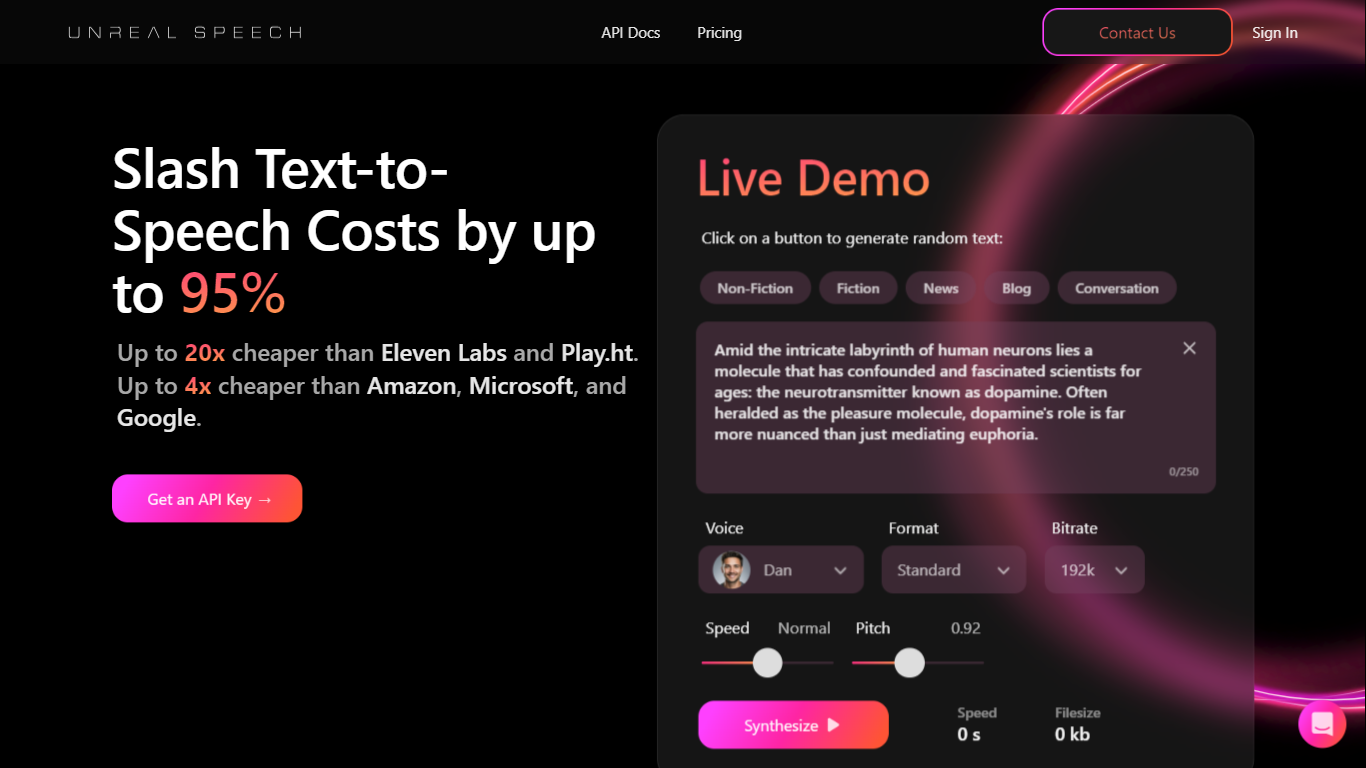

Qu'est-ce que Unreal Speech?
Unreal Speech est une API de synthèse vocale prête à la production, construite sur le moteur TTS open source Kokoro. Elle offre aux développeurs et aux entreprises une synthèse vocale naturelle à une fraction du coût d'ElevenLabs, Amazon Polly, Google Cloud et Microsoft Azure. L'API diffuse l'audio en environ 300 millisecondes et prend en charge les travaux longue durée jusqu'à 10 heures par requête.
Kokoro fonctionne avec un modèle décodage seul de 82 millions de paramètres qui combine des idées de StyleTTS 2 et iSTFTNet. Vous disposez de 48 voix réparties sur huit langues, dont l'anglais américain et britannique, le mandarin, l'hindi, l'espagnol, le portugais, le japonais, le français et l'italien. Les horodatages par mot permettent aux applications de mettre en surbrillance le texte en synchronisation avec la lecture, ce qui améliore l'accessibilité, les interfaces de style karaoké, et les lecteurs interactifs.
L'API REST expose quatre points de terminaison : /stream pour une synthèse en moins d'une seconde jusqu'à 1 000 caractères, /speech pour jusqu'à 3 000 caractères avec des URL d'horodatage, /synthesisTasks pour des travaux asynchrones jusqu'à 500 000 caractères, et une route websocket /streamWithTimestamps pour audio en direct avec synchronisation des mots. Des SDK sont disponibles pour Python, Node.js et React Native, avec un code exemple sur la page d'accueil.
Kokoro TTS Studio sur unrealspeech.com propose une démo gratuite dans le navigateur pour tester les voix avant de s'inscrire. Les plans payants suppriment les exigences d'attribution pour l'audio commercial. Les clients entreprises sur la plateforme traitent des milliards de caractères chaque mois avec une disponibilité de 99,9 %.
SpeechGen
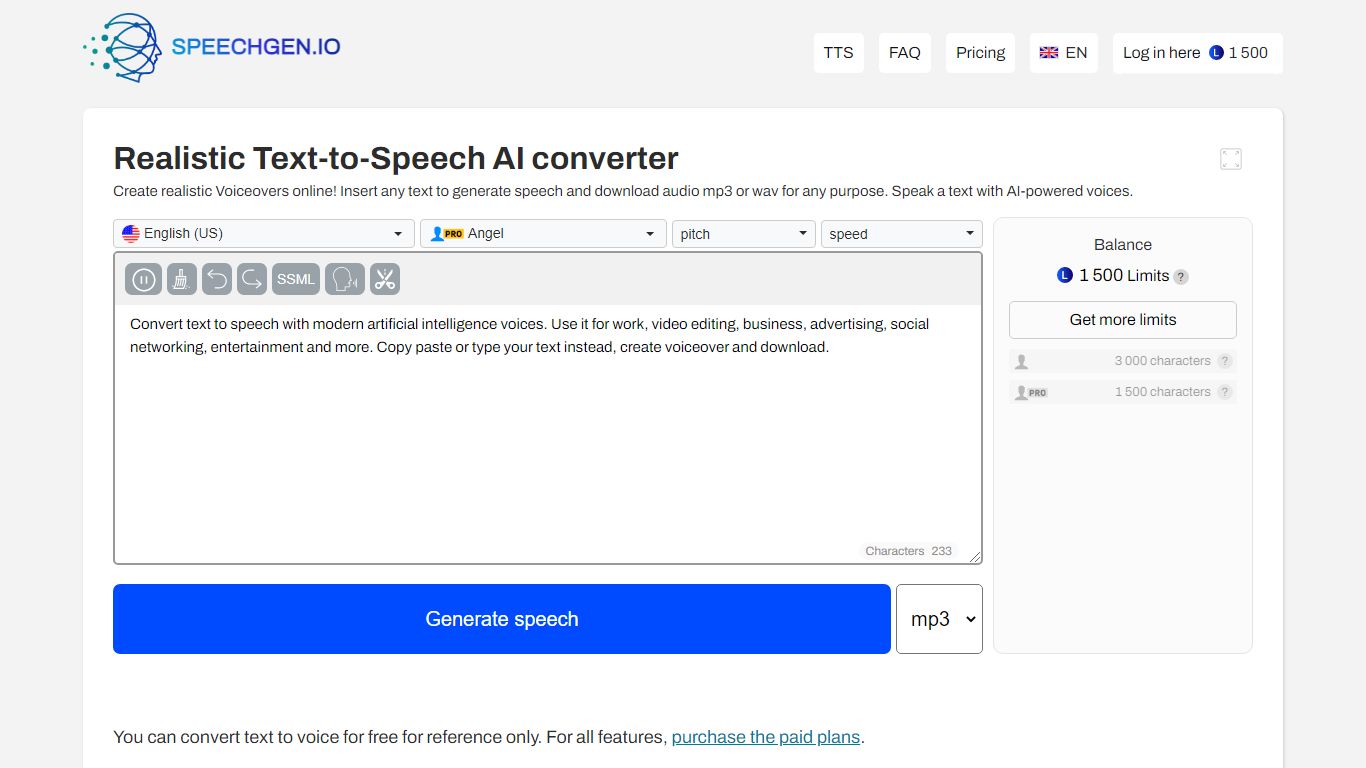
Qu'est-ce que SpeechGen?
SpeechGen est une plateforme de synthèse vocale alimentée par l'IA qui crée des voix-off réalistes rapidement et à moindre coût. Elle supporte plus de 1 000 voix naturelles dans 150 langues et accents, y compris des voix masculines, féminines, d'enfants et de personnes âgées. Les utilisateurs peuvent convertir de grands textes — jusqu'à 2 millions de caractères en une seule demande — ce qui la rend adaptée aux contenus longs comme les livres audio et les présentations. La plateforme offre une tarification flexible à la demande, avec des paiements uniques pour les limites de synthèse vocale, évitant ainsi les abonnements mensuels et permettant aux utilisateurs de maîtriser leurs dépenses efficacement. SpeechGen prend en charge l'utilisation commerciale, permettant aux créateurs de produire des audios pour les réseaux sociaux, podcasts, publicités, et plus encore. Les fonctionnalités avancées de personnalisation de la voix incluent l'ajustement de la vitesse, du ton, du stress, de la prononciation et des pauses, avec support SSML pour un contrôle précis. Elle convertit également les sous-titres et les documents en audio, améliorant l'accessibilité et la portée du contenu. Tous les fichiers audio générés sont téléchargeables dans plusieurs formats et stockés de manière sécurisée dans le cloud pour un accès et une gestion faciles. SpeechGen s'intègre parfaitement avec les logiciels populaires de montage vidéo et audio, en faisant un outil polyvalent pour les créateurs de contenu, éducateurs, marketeurs et développeurs.
Unreal Speech Votes positifs
SpeechGen Votes positifs
Unreal Speech Fonctionnalités principales
Diffuse jusqu'à 1 000 caractères en environ 300 ms via /stream
Les tâches de synthèse asynchrone gèrent jusqu'à 500 000 caractères par requête
Les horodatages par mot synchronisent la mise en surbrillance du texte avec la sortie audio
48 voix dans huit langues avec contrôle de la vitesse et de la hauteur
Le websocket /streamWithTimestamps fournit un audio en direct ainsi que des données de synchronisation
Les SDK Python, Node.js et React Native sont fournis avec des exemples de code
Une seule tâche de synthèse peut produire jusqu'à 10 heures d'audio
SpeechGen Fonctionnalités principales
🎙️ Plus de 1 000 voix naturelles en 150 langues pour des besoins variés
💰 Tarification à l'utilisation avec paiements uniques pour une dépense flexible
📝 Convertit de longs textes jusqu'à 2 millions de caractères en une seule fois
⚙️ Personnalisez facilement la vitesse, la tonalité, l'accentuation et la prononciation de la voix
📂 Téléchargez l'audio en MP3, WAV ou OGG et sauvegardez les fichiers dans le cloud
Unreal Speech Catégorie
- Text to Speech (TTS)
SpeechGen Catégorie
- Text to Speech (TTS)
Unreal Speech Type de tarification
- Freemium
SpeechGen Type de tarification
- Paid