Neuralangelo Research Reconstructs 3D Scenes | NVIDIA vs Text-To-4D
Na batalha entre Neuralangelo Research Reconstructs 3D Scenes | NVIDIA vs Text-To-4D, qual ferramenta AI 3D Generation sai por cima? Comparamos avaliações, preços, alternativas, votos positivos, recursos e muito mais.
Entre Neuralangelo Research Reconstructs 3D Scenes | NVIDIA e Text-To-4D, qual é superior?
Ao comparar Neuralangelo Research Reconstructs 3D Scenes | NVIDIA com Text-To-4D, ambas ferramentas são alimentadas por inteligência artificial na categoria de 3d generation, Com mais votos positivos, Text-To-4D é a escolha preferida. Text-To-4D recebeu 26 votos positivos, e Neuralangelo Research Reconstructs 3D Scenes | NVIDIA recebeu 6 votos positivos.
Acha que erramos? Vote e mostre quem manda!
Neuralangelo Research Reconstructs 3D Scenes | NVIDIA

O que é Neuralangelo Research Reconstructs 3D Scenes | NVIDIA?
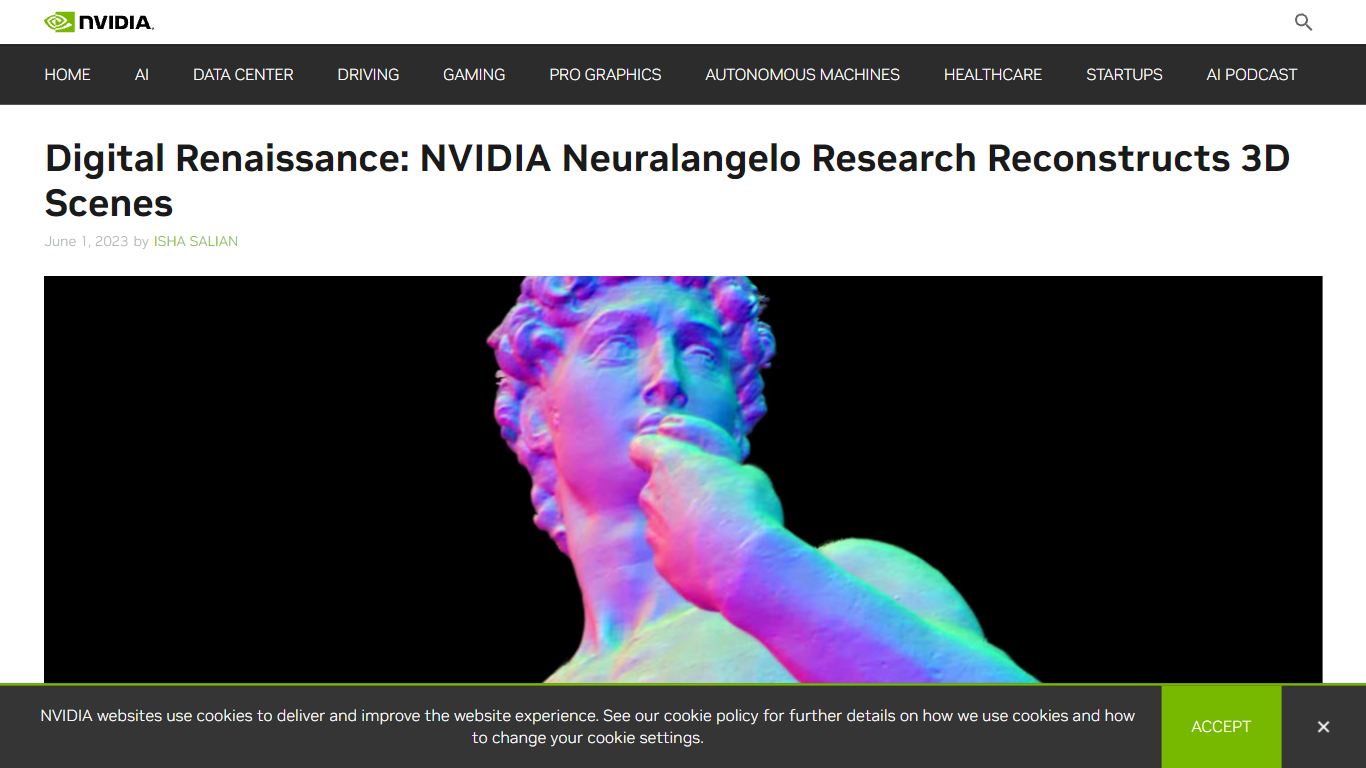
Neuralangelo é um modelo de IA desenvolvido pela NVIDIA Research que transforma clipes de vídeo 2D em estruturas 3D detalhadas usando redes neurais. Ele cria réplicas virtuais realistas de objetos como edifícios, esculturas e cenas complexas, capturando detalhes intrincados e texturas de múltiplos pontos de vista. Essa tecnologia é feita para profissionais criativos e desenvolvedores que atuam em realidade virtual, gêmeos digitais, robótica e desenvolvimento de jogos, permitindo que importem modelos 3D de alta fidelidade para seus fluxos de trabalho de design.
Diferentemente de métodos anteriores, Neuralangelo destaca-se por reproduzir materiais complexos como telhas de telhado, painéis de vidro e superfícies de mármore lisas com alta precisão. Ele usa primitivas gráficas neurais instantâneas, a tecnologia por trás do NVIDIA Instant NeRF, para captar detalhes finos e padrões de textura repetitivos que antes eram desafiadores. O modelo processa quadros selecionados de vídeos para estimar as posições da câmera e então constrói e refina uma representação 3D, de maneira semelhante a um escultor moldando um objeto a partir de múltiplos ângulos.
Neuralangelo suporta reconstrução tanto de objetos pequenos quanto de cenas em grande escala, incluindo interiores e exteriores de edifícios, demonstrado por modelos detalhados como a estátua de David, de Michelangelo, e o parque do campus da NVIDIA na Bay Area. Isso o torna uma ferramenta versátil para indústrias que necessitam de réplicas digitais realistas de ambientes e objetos do mundo real.
O modelo simplifica a criação de ativos virtuais utilizáveis a partir de filmagens capturadas até mesmo por smartphones, acelerando os fluxos de trabalho de artistas, designers e engenheiros. Ao reduzir a distância entre os mundos físico e digital, Neuralangelo aprimora o realismo e a eficiência de projetos nas áreas de entretenimento, design industrial e robótica.
A NVIDIA disponibilizou o Neuralangelo no GitHub, incentivando desenvolvedores e pesquisadores a explorarem e aprimorarem essa tecnologia. Representa um avanço significativo na reconstrução 3D, combinando renderização neural avançada com usabilidade prática para uma ampla gama de aplicações.
Text-To-4D

O que é Text-To-4D?
Text-To-4D, também conhecido como MAV3D (Make-A-Video3D), gera cenas dinâmicas tridimensionais a partir de descrições de texto simples. Ele utiliza um Neural Radiance Field (NeRF) dinâmico 4D otimizado para aparência consistente da cena, densidade e movimento, aproveitando um modelo de difusão Text-to-Video. Isso permite a criação de vídeos dinâmicos que podem ser visualizados de qualquer ângulo de câmera e integrados a diversos ambientes 3D.
Ao contrário dos métodos tradicionais de geração 3D, o MAV3D não requer dados de treinamento 3D ou 4D. Em vez disso, depende de um modelo Text-to-Video treinado exclusivamente com pares de texto-imagem e vídeos não rotulados, tornando-se acessível para usuários sem conjuntos de dados especializados. Essa abordagem abre novas possibilidades para criadores, desenvolvedores e pesquisadores interessados em gerar conteúdo dinâmico 3D imersivo a partir de comandos de texto.
A ferramenta foi desenhada para um amplo público, incluindo desenvolvedores de jogos, animadores e criadores de conteúdo de realidade virtual, que desejam produzir rapidamente cenas dinâmicas 3D sem modelagem ou animação manual. Ela oferece um valor único ao combinar geração orientada por texto com saída de cenas dinâmicas 3D, que podem ser usadas em aplicações interativas ou narrativa visual.
Tecnicamente, o método integra um NeRF 4D com um modelo de difusão baseado em Text-to-Video para garantir a consistência do movimento e da aparência ao longo do tempo e espaço. Como resultado, produz cenas dinâmicas suaves e realistas, que podem ser exploradas de múltiplos pontos de vista. O sistema melhora os resultados de bases internas anteriores, produzindo vídeos 3D de maior qualidade e mais coerentes a partir de entrada textual.
No geral, o Text-To-4D destaca-se como o primeiro método conhecido capaz de gerar cenas 3D totalmente dinâmicas a partir de texto, fechando a lacuna entre a geração de vídeos baseada em texto e a síntese de cenas 3D. Ele oferece uma solução flexível e inovadora para criar conteúdo imersivo sem a necessidade de dados 3D complexos ou animação manual.
Neuralangelo Research Reconstructs 3D Scenes | NVIDIA Votos positivos
Text-To-4D Votos positivos
Neuralangelo Research Reconstructs 3D Scenes | NVIDIA Recursos principais
🎥 Converte clipes de vídeo 2D em modelos 3D detalhados para uso fácil
🏛️ Captura texturas complexas como vidro e mármore com alta precisão
🖼️ Suporta reconstrução de objetos pequenos e cenas grandes
📱 Funciona com filmagens de smartphones, simplificando o processo de captura
💻 Disponibilidade open-source no GitHub para acesso dos desenvolvedores
Text-To-4D Recursos principais
🎥 Gera vídeos 3D dinâmicos a partir de comandos de texto para criação de conteúdo fácil
🌐 Visualize cenas geradas de qualquer ângulo de câmera para explorar ambientes livremente
🛠️ Não é necessário treinamento com dados 3D ou 4D, simplificando o processo de geração
⚙️ Utiliza um Campo Neural de Radiância 4D combinado com modelos de difusão para movimento suave
🔗 Os resultados podem ser integrados em diversos ambientes e aplicações 3D
Neuralangelo Research Reconstructs 3D Scenes | NVIDIA Categoria
- 3D Generation
Text-To-4D Categoria
- 3D Generation
Neuralangelo Research Reconstructs 3D Scenes | NVIDIA Tipo de tarifação
- Freemium
Text-To-4D Tipo de tarifação
- Free