
Last updated 10-31-2025
Category:
Reviews:
Join thousands of AI enthusiasts in the World of AI!
WebcrawlerAPI
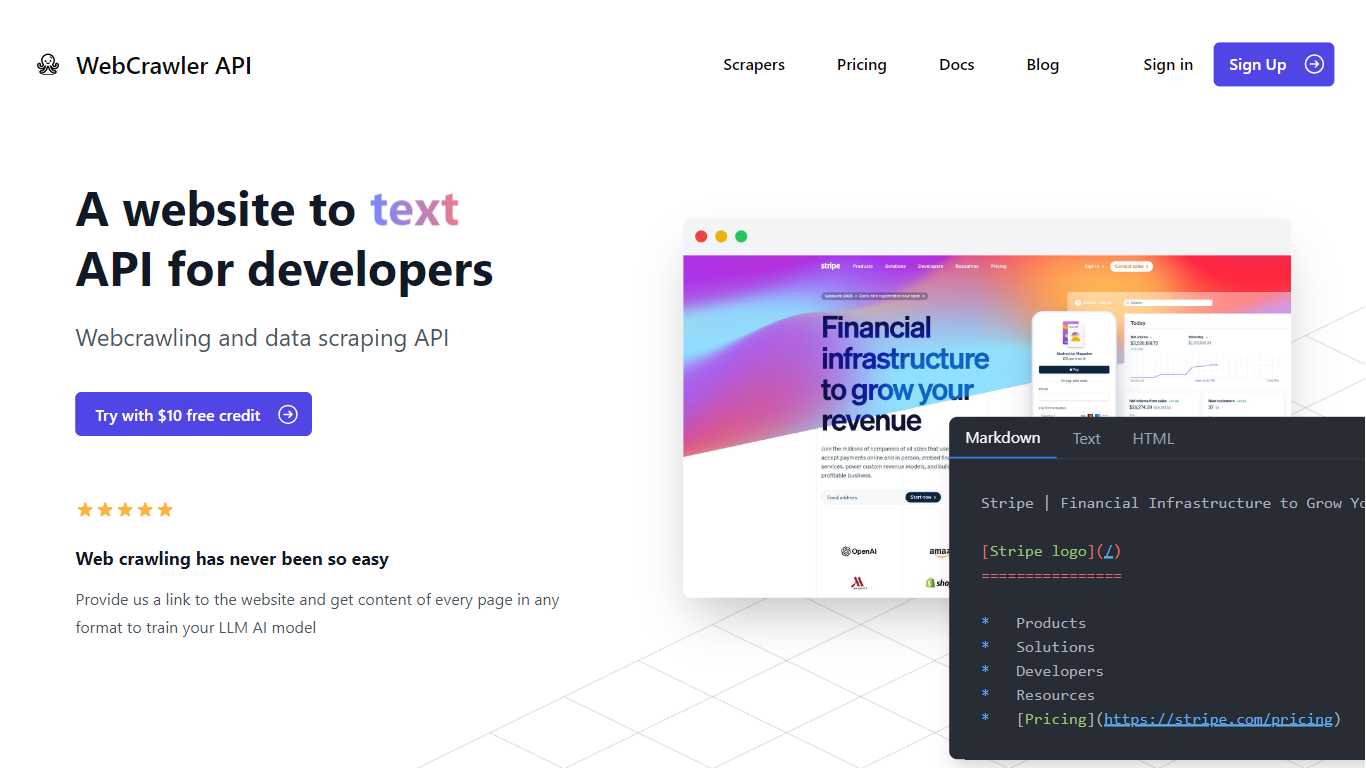
WebcrawlerAPI is a straightforward web crawling and data extraction service designed to simplify gathering content from almost any website. It offers a simple API call that returns clean, structured page content formatted for retrieval-augmented generation (RAG) or large language model (LLM) contexts. This makes it a great fit for developers, data scientists, and businesses building AI applications or needing reliable web data.
The service handles all the technical challenges behind the scenes, including managing proxies, retries, headless browsers, CAPTCHAs, and anti-bot protections. This means users don’t have to worry about complex setups or building custom crawlers. The API focuses on delivering accurate content parsing, extracting the main content in Markdown or plain text formats.
WebcrawlerAPI supports no-code integrations, allowing users to quickly add web crawling to their workflows without writing code. It boasts a 91% success rate and an average crawl time of about 9 seconds, making it both reliable and efficient. The pricing model is simple and usage-based, with no subscriptions or hidden fees.
Support is provided by real engineers, not chatbots, ensuring users get practical help when needed. The tool is especially useful for those working on RAG systems or training AI models who need clean, ready-to-use web content. Its focus on ease of integration and production-ready crawling sets it apart from many other scraping tools.
Overall, WebcrawlerAPI is a practical choice for anyone needing scalable, accurate web data extraction without the hassle of managing the underlying infrastructure or anti-bot challenges.
📡 Easy API access delivers web content fast
🛠️ Handles proxies, retries, and CAPTCHAs automatically
📄 Extracts main page content in Markdown or text
⚙️ No-code integrations for quick setup without coding
👩💻 Real human support for integration help
Handles complex crawling challenges like CAPTCHAs and anti-bot automatically
Delivers clean, structured content ready for AI and RAG use cases
Supports no-code integration for easy setup without programming
Offers real human support for faster problem resolution
Simple pay-as-you-go pricing with no subscriptions
No free tier or trial mentioned for testing before purchase
Average crawl time around 9 seconds may be slower than some competitors
Can I crawl specific pages or entire websites with WebcrawlerAPI?
Yes, WebcrawlerAPI lets you crawl individual pages or full websites by providing the URLs you want to extract content from.
Is WebcrawlerAPI suitable for building retrieval-augmented generation (RAG) systems?
Absolutely. The API returns content formatted for RAG or LLM contexts, making it ideal for AI applications that require clean, structured web data.
Do I need to manage proxies or anti-bot measures when using WebcrawlerAPI?
No, WebcrawlerAPI handles proxies, retries, headless browsers, CAPTCHAs, and anti-bot protections automatically so you don’t have to.
Can I integrate WebcrawlerAPI without writing code?
Yes, the service supports no-code integrations, allowing you to add web crawling to your workflows quickly and easily.
Is there a subscription fee for using WebcrawlerAPI?
No, WebcrawlerAPI uses a pay-as-you-go pricing model with no subscription or hidden fees.
What kind of support does WebcrawlerAPI offer?
You get real human support from engineers, not chatbots, to help with integration and any issues you encounter.
How fast is the crawling process with WebcrawlerAPI?
On average, WebcrawlerAPI completes a crawl in about 9 seconds with a 91% success rate.