Voice to Text 对比 Deep Voice 3
探索 Voice to Text 和 Deep Voice 3 的对决,找出哪个 AI Text to Speech (TTS) 工具获胜。我们分析赞成票、功能、评论、定价、替代品等等。
在 Voice to Text 和 Deep Voice 3 的对决中,哪一个夺冠?
当我们将Voice to Text与Deep Voice 3进行对比时,两者都是AI操作的text to speech (tts)工具,并将它们并排放置时,我们可以发现几个重要的相似之处和分歧。 就赞成票而言,没有明显的赢家,因为这两种工具都获得了相同的数量。 权力掌握在你手中!投票并参与决定获胜者。
不同意结果?投票支持您最喜欢的工具,帮助它获胜!
Voice to Text
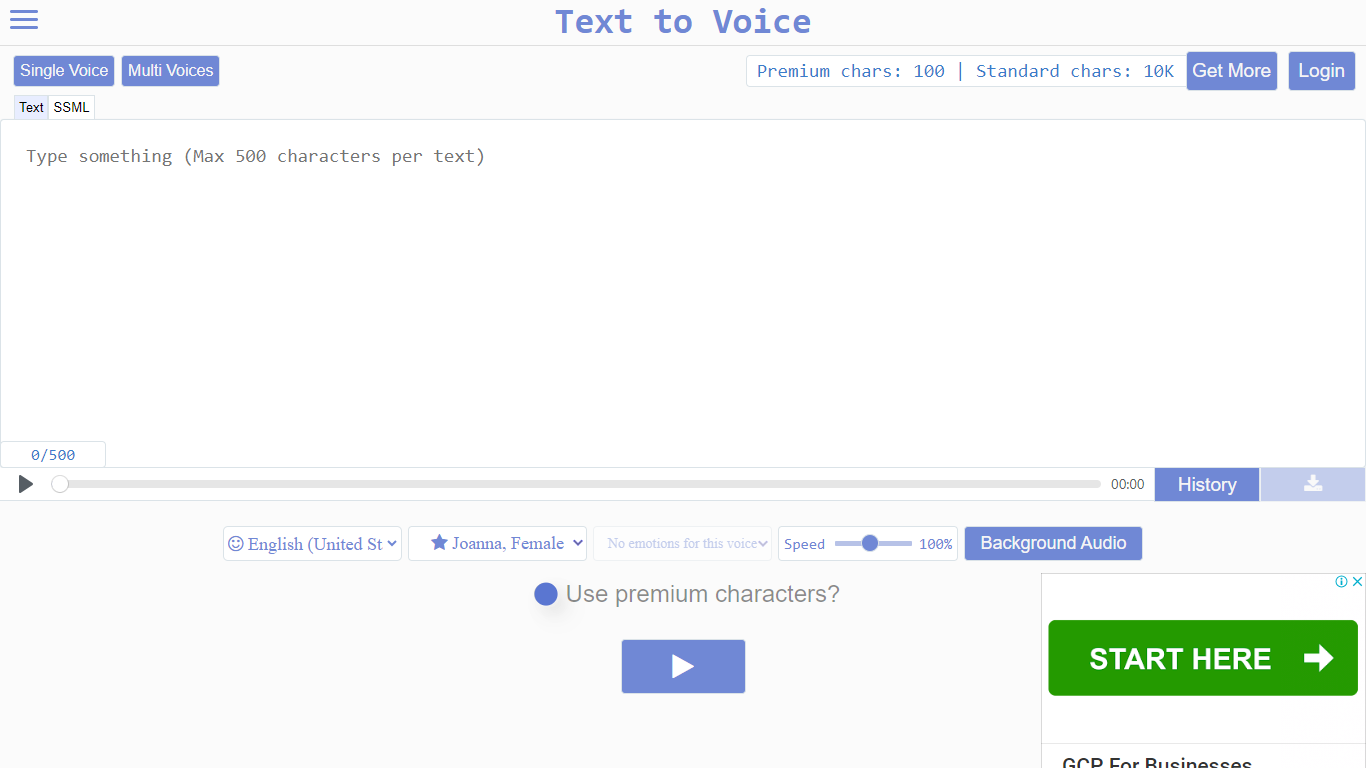

什么是 Voice to Text?
Voice to Text 提供免费的英语文本转语音在线转换器,能将书面文本转变为自然、逼真的人声。它支持多种情感表达,让用户可以在配音中加入喜悦、愤怒或惊讶等情感。该工具配备了第二代语音,实现了超逼真的音频效果,每次播放时都能改变语调,使反复聆听更具吸引力。
用户可以轻松选择语言、语音、说话风格和情感,然后转换文本,并可将音频下载为MP3文件。高品质语音选项通过先进算法提升真实感,产生更少机器感、更具说服力的语音。这一高级功能需使用付费字符,用户每天免费获得,也可以额外购买。
该平台适用于内容创作者、教育工作者、市场营销人员以及社交媒体影响者,帮助他们为视频或演示提供专业的配音,无需自己录音。它可以在Mac OS和Windows平台上的网页界面流畅运行,确保不同设备的可达性。
安全性是优先考虑的,生成的音频文件会被暂时存储,拥有随机ID,定期删除以保护用户隐私。所有文本转语音处理都在服务器端完成,保证了快速的性能,且不会对用户设备造成负担。
该工具特别适合为Instagram、TikTok等社交媒体平台制作配音,帮助视频显得更专业、更易于理解。其快速转换速度和高音频质量,使其成为需要快速、逼真且带有情感细节语音生成的用户的实用选择。
Deep Voice 3
什么是 Deep Voice 3?
Deep Voice 3 是一个开源的文本转语音系统,它采用全卷积神经网络将文本转换为自然的语音。它支持单一说话人和多说话人模型,能够生成不同声音和口音的语音。该系统设计具有高效扩展性,处理大量数据集和训练速度快于传统的TTS模型。
其架构包括处理文本输入的编码器、基于注意力机制的解码器(预测梅尔频谱图)以及生成声码器参数进行波形合成的转换网络。这种设计有助于产生清晰自然的语音,误读率更低。Deep Voice 3 还支持用音素、字符或混合输入进行训练,从而提高发音准确性。
最新的实现展示了模型从具有不同口音和年龄的多说话人合成语音的能力,体现了其多用性。包括英格兰南部和苏格兰在内的各种英语口音的音频样本,突显了其适应不同语音风格的能力。
Deep Voice 3 适合开发者和研究者,尤其是那些希望构建可扩展、高质量TTS应用的用户。其开源性质允许定制和实验不同的模型配置及数据集。
虽然核心技术与原始设计保持一致,但社区的持续努力正致力于提升训练效率和扩展多说话人能力。该系统的模块化结构便于与其他语音处理工具和声码器整合。
总体而言,Deep Voice 3 在速度、可扩展性和语音质量之间实现了良好的平衡,是从事语音合成项目、需要跨声音和语言的灵活性的技术人员的宝贵资源。
关于详细的技术细节和实现指导,原始研究论文和开源仓库提供了全面的资源。
Voice to Text 赞同数
Deep Voice 3 赞同数
Voice to Text 顶级功能
🎭 情感语音风格:为声音添加喜悦或愤怒等情感,使朗读更具表现力。
🎧 第2代音色:体验超逼真的声音,每次播放时音调都有变化。
💾 免费MP3下载:无需额外费用,即可即时保存生成的配音。
⚡ 快速转换:即使在较慢的网络环境下,也能在几秒钟内生成语音输出。
🔒 安全处理:音频文件以随机ID临时存储,并定期删除。
Deep Voice 3 顶级功能
🎤 支持多说话人,涵盖多种口音和年龄,呈现多样化声音
⚡ 训练速度快,加速模型开发进程
🧩 灵活的输入选项,可使用音素、字符或两者结合,实现更佳发音效果
🔊 生成梅尔频率尺度的声谱图,实现高质量音频合成
🔧 开源代码库,支持定制与集成
Voice to Text 类别
- Text to Speech (TTS)
Deep Voice 3 类别
- Text to Speech (TTS)
Voice to Text 定价类型
- Freemium
Deep Voice 3 定价类型
- Freemium