
最后更新 10-23-2025
分类:
Reviews:
Join thousands of AI enthusiasts in the World of AI!
WebcrawlerAPI
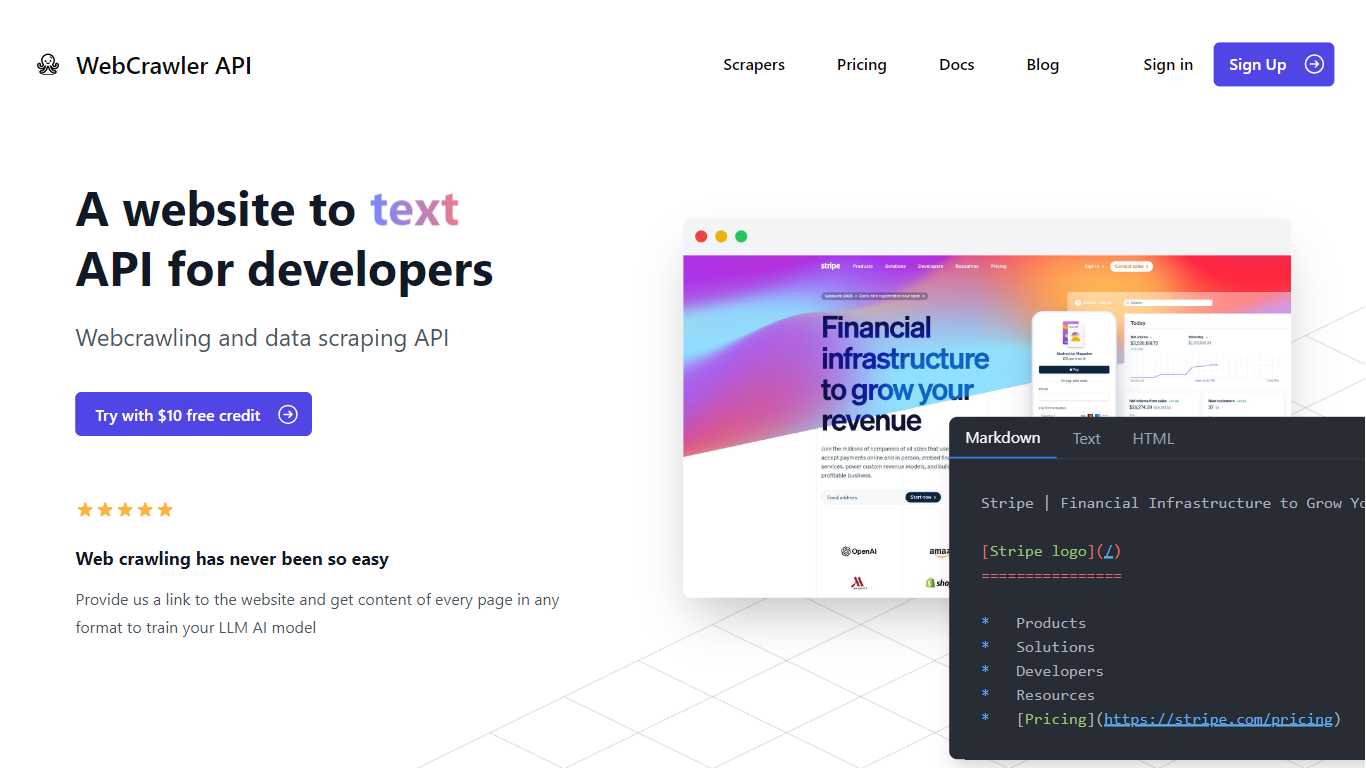
Webcrawlerapi 是一款功能强大的工具,可让网络数据提取变得非常简单。只需一个简单的 API 调用,用户就可以从几乎任何网站提取内容 - 无需构建自定义爬虫或担心复杂的设置。无论您是在培训法学硕士还是只需要结构化数据,此工具都旨在为您节省时间和麻烦。
对于需要可扩展、可靠解决方案的开发人员、数据科学家和企业来说,它特别方便。Webcrawlerapi 处理棘手的部分 - 例如处理内部链接、击败反机器人系统以及保持数据清洁 - 因此您不必这样做。
它最大的优势之一?速度和可靠性。它拥有 90% 的成功率,平均抓取时间仅为 7.3 秒。此外,定价非常简单:按使用量付费,无需订阅或隐藏费用。无论您抓取几页还是数百万页,Webcrawlerapi 都能让事情顺利、快速且经济高效。
高成功率:网页抓取成功率达到90%,确保为您的项目提取可靠的数据。
抓取速度快:平均抓取时间为7.3秒,可快速检索和分析数据。
全面的链接处理:通过删除重复项和清理 URL 有效地管理内部链接,简化数据提取过程。
强大的反机器人解决方案:轻松浏览 CAPTCHA、IP 阻止和速率限制,确保不间断访问网络数据。
灵活的定价模式:享受按使用量付费的定价结构,无隐藏费用,可根据抓取的页面数量实现经济高效的使用。
什么是 Webcrawlerapi?
Webcrawlerapi 是一款网页抓取和数据提取工具,为用户提供 API,以便高效地从网站提取内容。它旨在简化网页抓取流程,让开发人员和企业能够轻松使用。
Webcrawlerapi 如何处理反机器人措施?
Webcrawlerapi 采用了先进的技术来应对 CAPTCHA 和 IP 阻止等反机器人措施。这确保用户可以访问所需的数据,而不会受到这些安全功能造成的中断。
平均爬行时间是多少?
Webcrawlerapi 的平均抓取时间约为 7.3 秒,让用户能够快速高效地为其项目检索数据。
使用 Webcrawlerapi 是否需要订阅费?
不是,Webcrawlerapi 采用即用即付的定价模式,这意味着用户只需为他们抓取的页面付费,无需支付任何订阅费或隐藏费用。
Webcrawlerapi使用什么技术?
Webcrawlerapi 利用各种技术来增强其功能,包括用于 JavaScript 渲染的 Puppeteer 和 Playwright,确保可靠、高效的网络爬虫。
我可以轻松集成 Webcrawlerapi 吗?
是的,Webcrawlerapi 设计用于轻松集成,只需要几行代码即可连接到您的应用程序,这对于开发人员来说非常方便。
我可以使用 Webcrawlerapi 提取哪些类型的数据?
用户可以从网站中提取各种类型的数据类型,包括文本、图像和结构化数据,这些数据可用于训练 AI 模型等各种应用。