ChatTTS vs Musicfy
In the battle of ChatTTS vs Musicfy, which AI Audio Generation tool comes out on top? We compare reviews, pricing, alternatives, upvotes, features, and more.
Between ChatTTS and Musicfy, which one is superior?
Upon comparing ChatTTS with Musicfy, which are both AI-powered audio generation tools, The users have made their preference clear, Musicfy leads in upvotes. Musicfy has received 73 upvotes from aitools.fyi users, while ChatTTS has received 6 upvotes.
Think we got it wrong? Cast your vote and show us who's boss!
ChatTTS

What is ChatTTS?
ChatTTS is an open-source text-to-speech model built for dialogue. The 2Noise team trained it on over 100,000 hours of Chinese and English speech so it sounds natural in back-and-forth conversation, not just scripted narration.
What sets it apart is prosody control at a granular level. The model can layer in laughter, pauses, and interjections, and it handles multiple speakers in a single session. That makes it a fit for LLM assistants, conversational audio, and dialogue-heavy multimedia.
Developers install it via pip or clone the GitHub repo. The open-source release on Hugging Face is a 40,000-hour base model under AGPLv3+. The team positions it for research and dialogue use cases, with contact at [email protected] for roadmap questions.
Musicfy
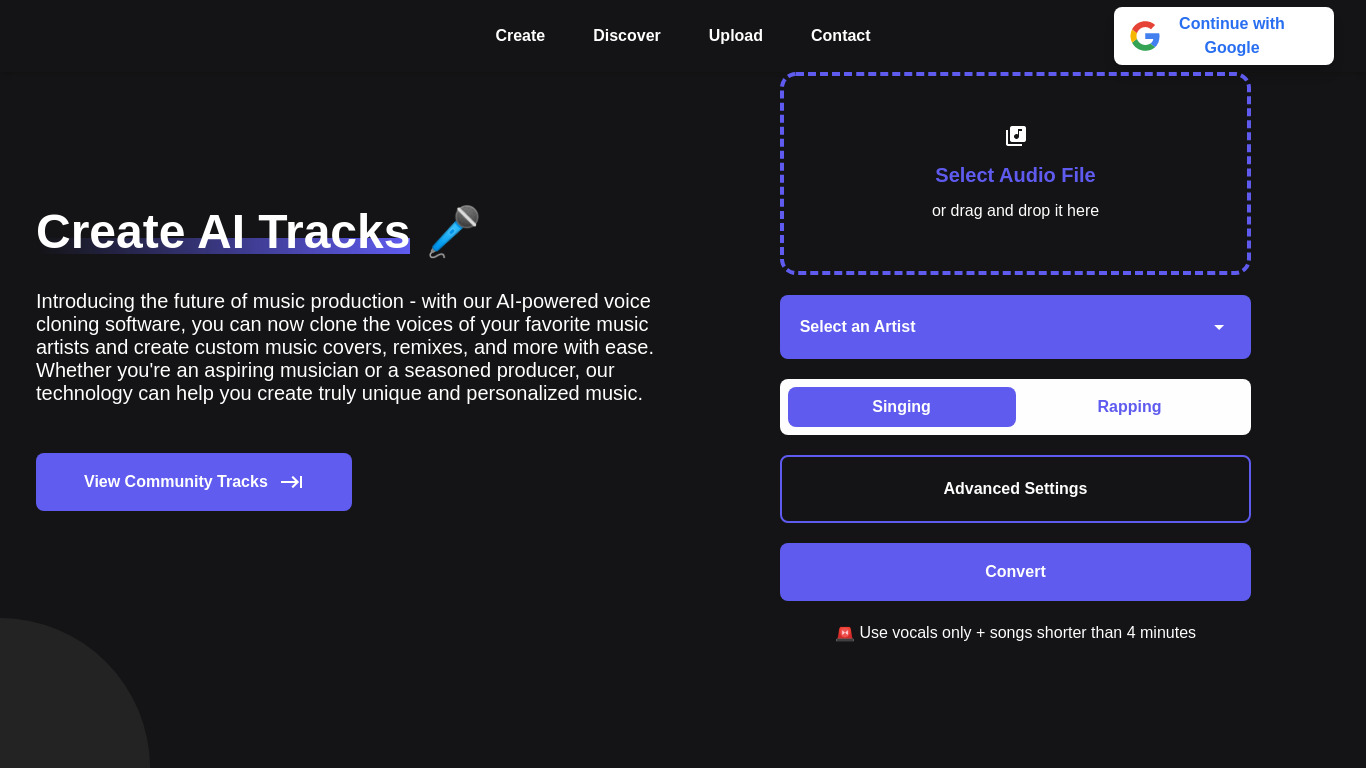
What is Musicfy?
Are you tired of limitations in your music production and always looking for new and exciting ways to enhance your sound? Look no further than our cutting-edge AI-powered voice cloning software! With our technology, you can clone the voices of your favorite music artists and create custom music covers, remixes, and more with unprecedented ease and flexibility.
Whether you're an aspiring musician or a seasoned producer, our software can help you bring your music to the next level by unlocking a world of creative possibilities. Say goodbye to the days of cookie-cutter covers and remixes, and hello to the future of music production!
ChatTTS Upvotes
Musicfy Upvotes
ChatTTS Top Features
Shapes laughter, pauses, and interjections into synthesized speech
Runs multi-speaker dialogue from a single inference call
Trained on 100,000+ hours of Chinese and English audio
Streams audio output for real-time playback
Install via pip or pull weights from Hugging Face
Musicfy Top Features
No top features listedChatTTS Category
- Audio Generation
Musicfy Category
- Audio Generation
ChatTTS Pricing Type
- Free
Musicfy Pricing Type
- Free