Farm3D vs Text-To-4D
When comparing Farm3D vs Text-To-4D, which AI 3D Generation tool shines brighter? We look at pricing, alternatives, upvotes, features, reviews, and more.
Between Farm3D and Text-To-4D, which one is superior?
When we put Farm3D and Text-To-4D side by side, both being AI-powered 3d generation tools, Text-To-4D is the clear winner in terms of upvotes. Text-To-4D has garnered 26 upvotes, and Farm3D has garnered 6 upvotes.
Does the result make you go "hmm"? Cast your vote and turn that frown upside down!
Farm3D
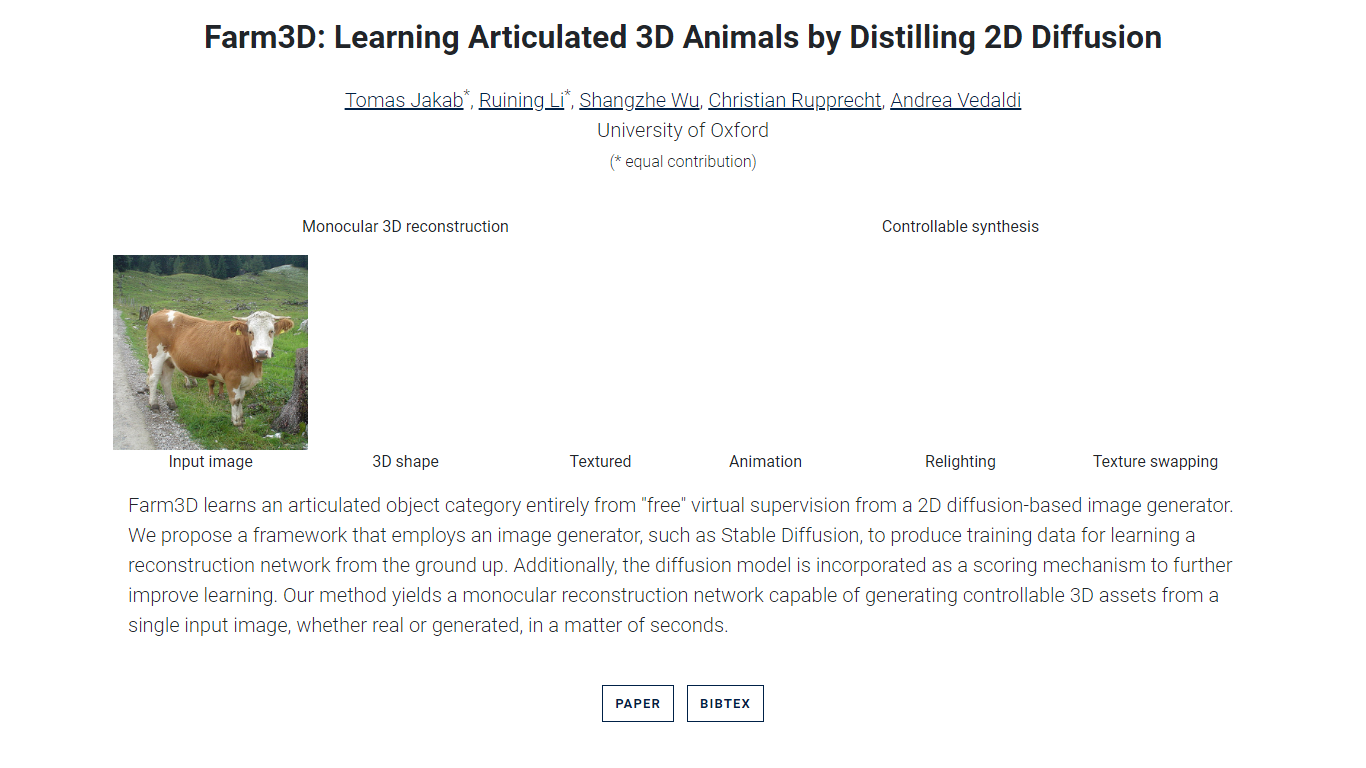

What is Farm3D?
Farm3D is a tool developed by the University of Oxford that creates articulated 3D animal models from a single image. It uses a unique approach by leveraging a 2D diffusion-based image generator, like Stable Diffusion, to train a network that reconstructs detailed 3D shapes without needing real 3D data. This method allows Farm3D to generate 3D models with fine details such as legs and ears, even though it was not trained on real images.
The tool supports controllable 3D synthesis, enabling users to adjust lighting, swap textures between models of the same animal category, and animate the shapes. It works with both real images and images generated by Stable Diffusion, producing 3D assets in seconds. Farm3D factors input images into components like articulated shape, appearance, viewpoint, and light direction, giving users control over the final model.
Farm3D also introduces the Animodel dataset, a collection of textured 3D meshes of articulated animals such as horses, cows, and sheep, with realistic poses. This dataset serves as a benchmark to evaluate the quality of single-view 3D reconstruction for articulated animals.
This tool is ideal for researchers, digital artists, and developers interested in 3D animal modeling, animation, and synthesis without requiring extensive 3D training data. Its novel use of diffusion models for virtual supervision and scoring sets it apart from traditional 3D reconstruction methods.
Farm3D's approach reduces the need for costly 3D annotations by using synthetic views generated and critiqued by diffusion models during training. This results in a monocular reconstruction network that is fast, flexible, and capable of producing high-quality 3D animal models with controllable features.
Text-To-4D

What is Text-To-4D?
Text-To-4D, also known as MAV3D (Make-A-Video3D), generates three-dimensional dynamic scenes from simple text descriptions. It uses a 4D dynamic Neural Radiance Field (NeRF) optimized for consistent scene appearance, density, and motion by leveraging a Text-to-Video diffusion model. This allows the creation of dynamic videos that can be viewed from any camera angle and integrated into various 3D environments.
Unlike traditional 3D generation methods, MAV3D does not require any 3D or 4D training data. Instead, it relies on a Text-to-Video model trained solely on text-image pairs and unlabeled videos, making it accessible for users without specialized datasets. This approach opens up new possibilities for creators, developers, and researchers interested in generating immersive 3D dynamic content from text prompts.
The tool is designed for a broad audience including game developers, animators, and virtual reality content creators who want to quickly produce dynamic 3D scenes without manual modeling or animation. It offers a unique value by combining text-driven generation with 3D dynamic scene output, which can be used in interactive applications or visual storytelling.
Technically, the method integrates a 4D NeRF with a diffusion-based Text-to-Video model to ensure motion and appearance consistency over time and space. This results in smooth, realistic dynamic scenes that can be explored from multiple viewpoints. The system improves upon previous internal baselines by producing higher quality and more coherent 3D videos from textual input.
Overall, Text-To-4D stands out as the first known method to generate fully dynamic 3D scenes from text, bridging the gap between text-based video generation and 3D scene synthesis. It offers a flexible and innovative solution for creating immersive content without the need for complex 3D data or manual animation.
Farm3D Upvotes
Text-To-4D Upvotes
Farm3D Top Features
🐾 Single-image 3D reconstruction creates detailed animal models quickly
🎨 Texture swapping lets you customize appearances between models
💡 Adjustable lighting enhances realism with relighting controls
🎬 Animation support adds movement to 3D animal shapes
🖼️ Uses synthetic views from Stable Diffusion for training without real 3D data
Text-To-4D Top Features
🎥 Generates dynamic 3D videos from text prompts for easy content creation
🌐 View generated scenes from any camera angle to explore environments freely
🛠️ No need for 3D or 4D training data, simplifying the generation process
⚙️ Uses a 4D Neural Radiance Field combined with diffusion models for smooth motion
🔗 Outputs can be integrated into various 3D environments and applications
Farm3D Category
- 3D Generation
Text-To-4D Category
- 3D Generation
Farm3D Pricing Type
- Freemium
Text-To-4D Pricing Type
- Free