WebcrawlerAPI vs UseScraper
When comparing WebcrawlerAPI vs UseScraper, which AI Web Scraping tool shines brighter? We look at pricing, alternatives, upvotes, features, reviews, and more.
In a comparison between WebcrawlerAPI and UseScraper, which one comes out on top?
When we put WebcrawlerAPI and UseScraper side by side, both being AI-powered web scraping tools, The users have made their preference clear, UseScraper leads in upvotes. UseScraper has attracted 7 upvotes from aitools.fyi users, and WebcrawlerAPI has attracted 6 upvotes.
Think we got it wrong? Cast your vote and show us who's boss!
WebcrawlerAPI
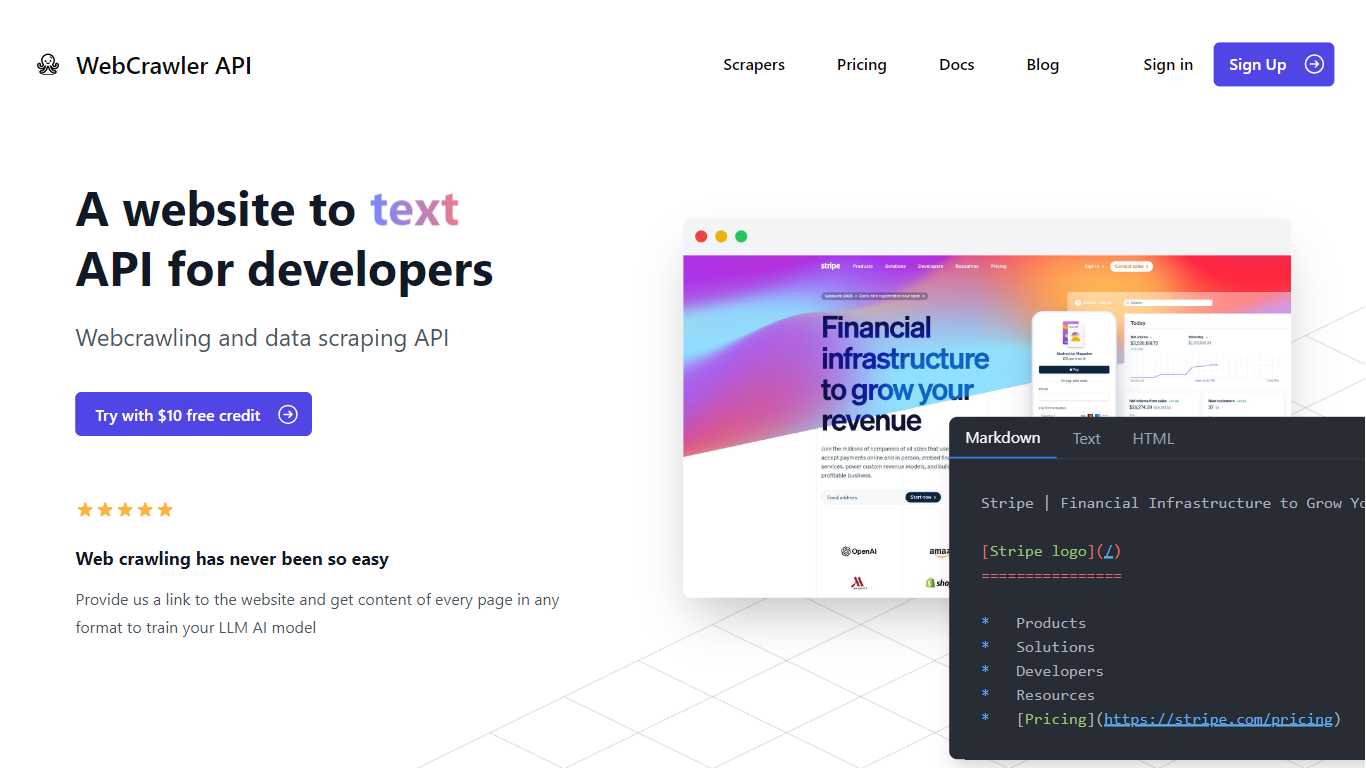

What is WebcrawlerAPI?
Webcrawlerapi is a powerful tool that makes web data extraction super easy. With just a simple API call, users can pull content from almost any website—no need to build a custom crawler or worry about complex setups. Whether you're training an LLM or just need structured data, this tool is built to save you time and headaches.
It’s especially handy for developers, data scientists, and businesses who want a scalable, reliable solution. Webcrawlerapi deals with the tricky parts—like handling internal links, beating anti-bot systems, and keeping your data clean—so you don’t have to.
One of its biggest perks? Speed and reliability. It boasts a 90% success rate and completes an average crawl in just 7.3 seconds. Plus, the pricing is refreshingly simple: pay for what you use, no subscriptions or hidden fees. Whether you're crawling a few pages or millions, Webcrawlerapi keeps things smooth, fast, and cost-effective.
UseScraper
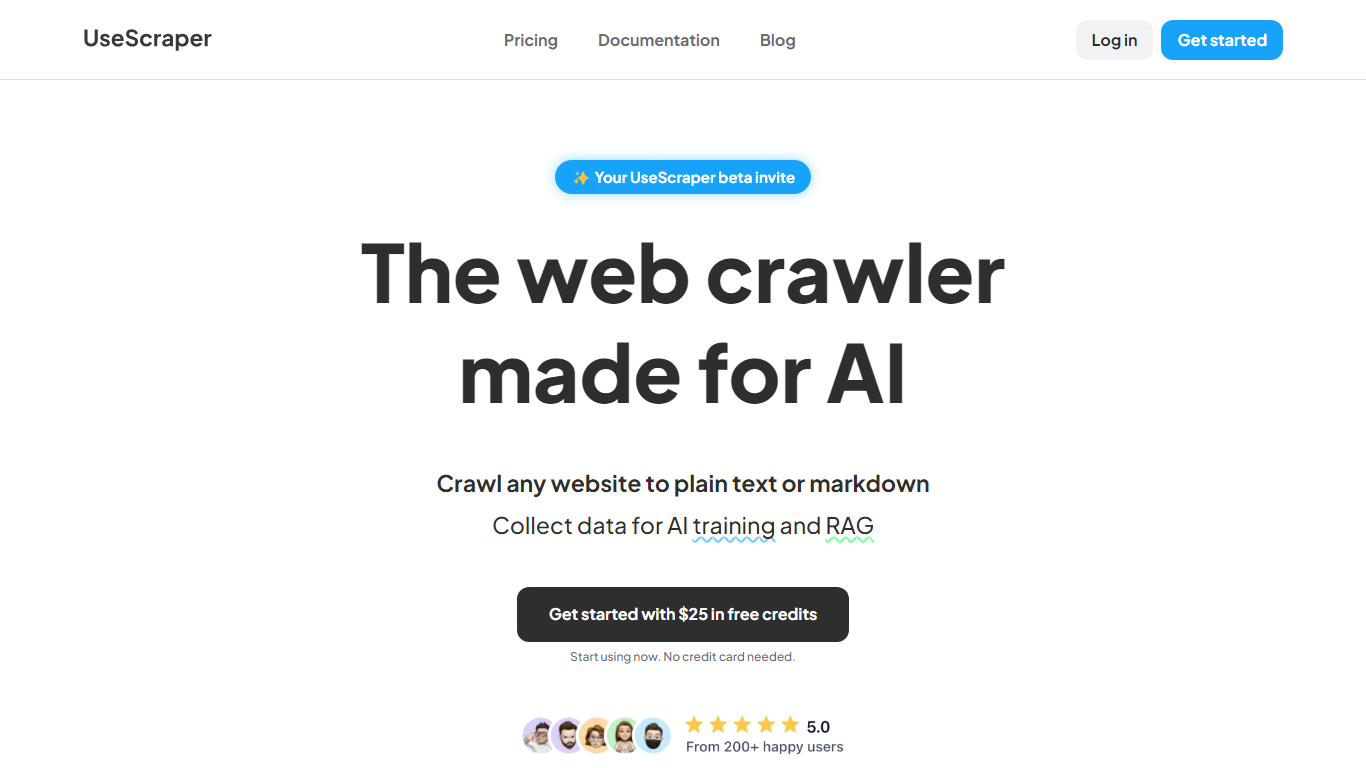
What is UseScraper?
Experience hyper-fast web crawling and scraping with UseScraper, a cutting-edge API designed for efficiency. Simplify data collection with a service that allows you to transform any website into plain text or markdown, perfect for AI training and RAG tasks. Start immediately with $25 in free credits, no credit card required. Our robust web crawling can process thousands of pages a minute, offering full browser rendering, even with complex JavaScript elements. Enjoy versatile content extraction in markdown, plain text, or HTML and stay ahead of rate limits with our automatic rotating proxies. Choose from flexible pricing plans and benefit from features like multi-site crawling, page exclusions, webhook updates, and a convenient output data store.
WebcrawlerAPI Upvotes
UseScraper Upvotes
WebcrawlerAPI Top Features
High Success Rate: Achieve a 90% success rate in crawling webpages, ensuring reliable data extraction for your projects.
Fast Crawling Speed: Experience an average crawling time of 7.3 seconds, allowing for quick data retrieval and analysis.
Comprehensive Link Handling: Manage internal links effectively by removing duplicates and cleaning URLs, simplifying the data extraction process.
Robust Anti-Bot Solutions: Navigate CAPTCHAs, IP blocks, and rate limits with ease, ensuring uninterrupted access to web data.
Flexible Pricing Model: Benefit from a pay-as-you-go pricing structure with no hidden fees, allowing for cost-effective usage based on the number of pages crawled.
UseScraper Top Features
Hyper-Fast Web Crawling: Crawl and scrape thousands of web pages per minute with an instantly scalable web crawler.
Markdown & Text Extraction: Perfectly convert website content to markdown or plain text ideal for use with AI systems.
Full Browser Rendering: Utilize headless Chrome browsing to render and scrape complex websites with JavaScript.
Automatic Rotating Proxies: Overcome scraping blocks with auto-rotating proxies that prevent rate limiting.
Flexible Pricing & Free Credits: Access UseScraper's services with no upfront cost and get started with $25 in free credits.
WebcrawlerAPI Category
- Web Scraping
UseScraper Category
- Web Scraping
WebcrawlerAPI Pricing Type
- Paid
UseScraper Pricing Type
- Freemium