DreamFusion vs Text-To-4D
Al comparar DreamFusion vs Text-To-4D, ¿cuál herramienta AI 3D Generation brilla con más intensidad? Examinamos precios, alternativas, votos positivos, características, opiniones, y más.
En una comparación entre DreamFusion y Text-To-4D, ¿cuál sale por encima?
Cuando ponemos DreamFusion y Text-To-4D uno al lado del otro, ambas siendo herramientas impulsadas por inteligencia artificial en la categoría de 3d generation, La comunidad ha hablado, Text-To-4D lidera con más votos positivos. Text-To-4D ha sido votado positivamente 26 veces por usuarios de aitools.fyi, y DreamFusion ha sido votado positivamente 6 veces.
¿No es lo tuyo? ¡Vota por tu herramienta preferida y agita las cosas!
DreamFusion
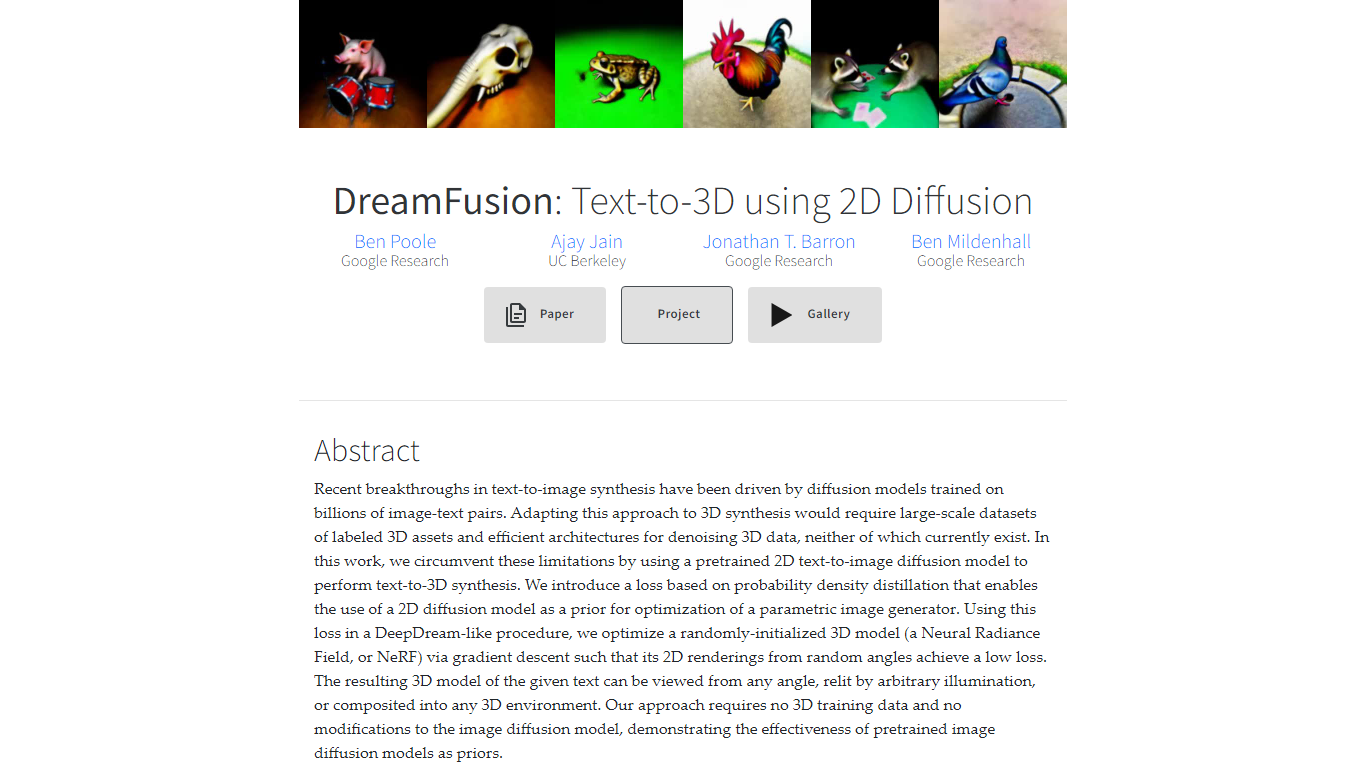

¿Qué es DreamFusion?
DreamFusion transforma descripciones de texto en modelos 3D detallados utilizando un modelo de difusión de texto a imagen en 2D preentrenado. Evita la necesidad de grandes conjuntos de datos 3D al optimizar los campos de radiación neuronal (NeRF) mediante una novedosa pérdida de muestreo de destilación de puntuaciones (Score Distillation Sampling). Este método permite que DreamFusion genere escenas en 3D que se pueden ver desde cualquier ángulo, volver a iluminarlas con diferentes luces y integrarlas en diversos entornos 3D.
La herramienta está dirigida a creadores y desarrolladores que desean producir rápidamente activos en 3D sin requerir un conocimiento profundo en modelado 3D ni acceso a datos extensos en 3D. Ofrece una forma de generar objetos que se puedan volver a iluminar, con profundidad precisa y normales de superficie, mejorando el realismo en escenas virtuales.
El valor de DreamFusion radica en su capacidad para aprovechar modelos de difusión 2D existentes, como Imagen, para guiar la síntesis en 3D, evitando la complejidad de entrenar nuevos modelos 3D. También soporta la exportación de NeRFs a mallas mediante cubos de Marching (marching cubes), facilitando el uso de modelos generados en programas 3D comunes.
Desde un punto de vista técnico, DreamFusion utiliza la muestra de destilación de puntuaciones para optimizar los parámetros en 3D de modo que las imágenes renderizadas coincidan con las expectativas del modelo de difusión. Reguladores adicionales mejoran la calidad de la geometría, dando lugar a formas coherentes con propiedades superficiales detalladas.
Este enfoque demuestra cómo los priors de difusión en 2D pueden extenderse más allá de las imágenes hacia la creación de contenido en 3D, abriendo nuevas posibilidades para la generación de 3D basada en texto sin necesidad de datos o arquitecturas especializadas.
Los usuarios pueden explorar una galería de objetos y escenas diversos, mostrando la variedad de resultados posibles a partir de simples indicaciones de texto. DreamFusion sigue evolucionando como una plataforma basada en la investigación que conecta el texto, la difusión en 2D y el modelado en 3D.
Text-To-4D

¿Qué es Text-To-4D?
Text-To-4D, también conocido como MAV3D (Make-A-Video3D), genera escenas dinámicas tridimensionales a partir de descripciones de texto simples. Utiliza un campo de radiación neural dinámico de 4D (NeRF) optimizado para mantener la apariencia, densidad y movimiento coherentes de la escena, aprovechando un modelo de difusión de Texto-a-Video. Esto permite crear videos dinámicos que pueden ser visualizados desde cualquier ángulo de cámara y integrados en diversos entornos 3D.
A diferencia de los métodos tradicionales de generación 3D, MAV3D no requiere datos de entrenamiento en 3D o 4D. En su lugar, se basa en un modelo de Texto-a-Video entrenado únicamente con pares de texto e imagen y videos no etiquetados, lo que lo hace accesible para usuarios sin conjuntos de datos especializados. Este enfoque abre nuevas posibilidades para creadores, desarrolladores e investigadores interesados en generar contenido dinámico 3D inmersivo a partir de indicaciones de texto.
La herramienta está diseñada para un público amplio, incluyendo desarrolladores de juegos, animadores y creadores de contenido de realidad virtual que desean producir rápidamente escenas dinámicas en 3D sin necesidad de modelado o animación manual. Ofrece un valor único al combinar generación basada en texto con salida de escenas dinámicas en 3D, que puede ser utilizada en aplicaciones interactivas o narrativas visuales.
Desde el punto de vista técnico, el método integra un NeRF de 4D con un modelo de difusión de Texto-a-Video para garantizar la coherencia de movimiento y apariencia a lo largo del tiempo y el espacio. Esto resulta en escenas dinámicas suaves y realistas que pueden ser exploradas desde múltiples puntos de vista. El sistema mejora las bases internas previas al producir videos en 3D de mayor calidad y coherencia a partir de entradas textuales.
En general, Text-To-4D destaca como el primer método conocido para generar escenas 3D completamente dinámicas a partir de texto, cerrando la brecha entre la generación de videos basada en texto y la síntesis de escenas en 3D. Ofrece una solución flexible e innovadora para crear contenido inmersivo sin necesidad de datos complejos en 3D o animación manual.
DreamFusion Votos positivos
Text-To-4D Votos positivos
DreamFusion Características principales
🎨 La conversión de texto a 3D crea modelos 3D detallados a partir de indicaciones de texto simples
🔄 Visualiza objetos 3D generados desde cualquier ángulo para una exploración completa de la escena
💡 Los modelos con iluminación ajustable se adaptan a diferentes condiciones de luz de manera realista
🖥️ Exporta modelos NeRF a mallas para su uso en software 3D estándar
⚙️ Utiliza Score Distillation Sampling para optimizar escenas 3D con guía de difusión 2D
Text-To-4D Características principales
🎥 Genera videos 3D dinámicos a partir de indicaciones de texto para una creación de contenido sencilla
🌐 Visualiza escenas generadas desde cualquier ángulo de cámara para explorar ambientes libremente
🛠️ No se requieren datos de entrenamiento 3D o 4D, simplificando el proceso de generación
⚙️ Utiliza un Campo de Radiancia Neural 4D combinado con modelos de difusión para un movimiento suave
🔗 Las salidas pueden integrarse en diversos entornos y aplicaciones 3D
DreamFusion Categoría
- 3D Generation
Text-To-4D Categoría
- 3D Generation
DreamFusion Tipo de tarificación
- Free
Text-To-4D Tipo de tarificación
- Free