Voice to Text vs Deep Voice 3
Explora el enfrentamiento entre Voice to Text vs Deep Voice 3 y descubre qué herramienta AI Text to Speech (TTS) gana. Analizamos votos positivos, características, opiniones, precios, alternativas, y más.
En un enfrentamiento entre Voice to Text y Deep Voice 3, ¿cuál se lleva la corona?
Al contrastar Voice to Text con Deep Voice 3, ambas son herramientas excepcionales operadas por inteligencia artificial en la categoría de text to speech (tts), y al colocarlas lado a lado, podemos notar varias similitudes y divergencias cruciales. No hay un claro ganador en términos de votos positivos, ya que ambas herramientas han recibido la misma cantidad. ¡El poder está en tus manos! Emite tu voto y participa en la decisión del ganador.
¿No estás de acuerdo con el resultado? ¡Vota por tu herramienta favorita y ayúdala a ganar!
Voice to Text
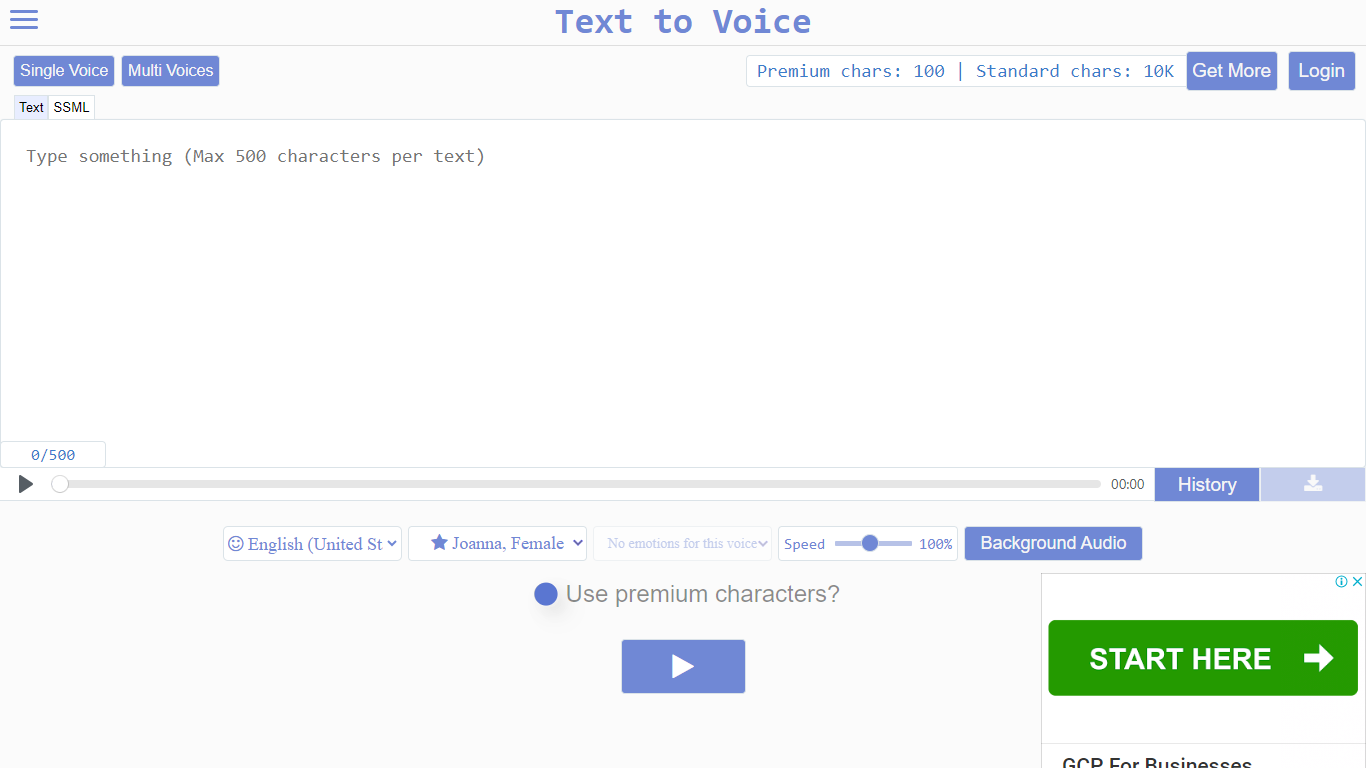

¿Qué es Voice to Text?
Voice to Text ofrece un convertidor gratuito en línea de texto en inglés a habla que transforma textos escritos en palabras habladas de manera natural y humana. Soporta una amplia gama de emociones, permitiendo a los usuarios añadir sentimientos como alegría, ira o sorpresa a sus locuciones. La herramienta cuenta con voces de Generación 2, que proporcionan un audio ultra realista que cambia de tono en cada reproducción, haciendo que escuchar repetidamente sea más atractivo.
Los usuarios pueden seleccionar fácilmente idioma, voz, estilo de habla y emoción antes de convertir el texto, con la opción de descargar el audio como un archivo MP3. Una opción de voz premium mejora el realismo utilizando un algoritmo avanzado, produciendo un habla menos robótica y más convincente. Esta función premium requiere caracteres premium, que los usuarios reciben diariamente de forma gratuita o pueden comprar adicionalmente.
La plataforma está diseñada para diversos usuarios, incluyendo creadores de contenido, educadores, marketers e influencers en redes sociales que desean narraciones profesionales para videos o presentaciones sin grabar su propia voz. Funciona de manera fluida en Mac OS y Windows mediante una interfaz web, asegurando accesibilidad en varios dispositivos.
La seguridad es una prioridad; los archivos de audio generados se almacenan temporalmente con IDs aleatorios y se eliminan regularmente para proteger la privacidad del usuario. Todo el procesamiento de texto a voz se realiza en el servidor, garantizando un rendimiento rápido sin cargar el dispositivo del usuario.
La herramienta es especialmente útil para crear locuciones para Instagram, TikTok y otras plataformas sociales, ayudando a que los videos sean más profesionales y fáciles de entender. Su velocidad de conversión rápida y alta calidad de audio la convierten en una opción práctica para quienes necesitan generación rápida y realista de voces con matices emocionales.
Deep Voice 3
¿Qué es Deep Voice 3?
Deep Voice 3 es un sistema de texto a voz de código abierto que utiliza una red neuronal convolucional completa para convertir texto en un habla de sonido natural. Soporta modelos de un solo hablante y de múltiples hablantes, lo que le permite generar voces en diferentes tonos y acentos. El sistema está diseñado para escalar eficientemente, manejando grandes conjuntos de datos y entrenando rápidamente en comparación con los modelos TTS tradicionales.
La arquitectura incluye un codificador que procesa las entradas de texto, un decodificador basado en atención que predice espectrogramas en escala mel, y una red conversora que genera parámetros para el vocoder para la síntesis de la forma de onda. Este diseño ayuda a producir un habla claro y natural con menos errores de pronunciación. Deep Voice 3 también soporta entrenamiento con entradas de fonemas, caracteres o una mezcla de ambos, lo que mejora la exactitud en la pronunciación.
Implementaciones recientes han demostrado la capacidad del modelo para sintetizar habla de múltiples hablantes con acentos y edades distintas, mostrando su versatilidad. Las muestras de audio de diversos acentos en inglés, incluido el sur de Inglaterra y escocés, resaltan su adaptabilidad a diferentes estilos de habla.
Deep Voice 3 es apto para desarrolladores e investigadores interesados en construir aplicaciones TTS escalables y de alta calidad. Su naturaleza de código abierto permite la personalización y experimentación con diferentes configuraciones de modelos y conjuntos de datos.
Aunque la tecnología central permanece consistente con el diseño original, los esfuerzos comunitarios en curso se enfocan en mejorar la eficiencia del entrenamiento y en ampliar las capacidades de múltiples hablantes. La estructura modular del sistema facilita su integración con otras herramientas de procesamiento de voz y vocoders.
En general, Deep Voice 3 ofrece un equilibrio entre velocidad, escalabilidad y calidad de voz, siendo un recurso valioso para quienes trabajan en proyectos de síntesis de voz que requieren flexibilidad en voces e idiomas.
Para obtener detalles técnicos y orientación de implementación, el artículo de investigación original y los repositorios de código abierto proporcionan recursos detallados.
Voice to Text Votos positivos
Deep Voice 3 Votos positivos
Voice to Text Características principales
🎭 Estilos de Voz Emocionales: Añade sentimientos como alegría o ira a las voces para una narración expresiva.
🎧 Voces Gen2: Experimenta voces ultra realistas que varían el tono en cada reproducción.
💾 Descargas Gratis de MP3: Guarda tus voces generadas al instante sin coste adicional.
⚡ Conversión Rápida: Obtén la salida de voz en segundos, incluso con conexiones a internet lentas.
🔒 Procesamiento Seguro: Los archivos de audio se almacenan temporalmente con identificadores aleatorios y se eliminan regularmente.
Deep Voice 3 Características principales
🎤 Soporte para múltiples hablantes con acentos y edades variadas para voces diversas
⚡ Velocidades de entrenamiento rápidas que permiten un desarrollo más ágil del modelo
🧩 Opciones de entrada flexibles utilizando fonemas, caracteres o ambos para una mejor pronunciación
🔊 Genera espectrogramas en escala mel para una síntesis de audio de alta calidad
🔧 Código fuente abierto que permite la personalización e integración
Voice to Text Categoría
- Text to Speech (TTS)
Deep Voice 3 Categoría
- Text to Speech (TTS)
Voice to Text Tipo de tarificación
- Freemium
Deep Voice 3 Tipo de tarificación
- Freemium