FinetuneFast vs ggml.ai
Dans la bataille de FinetuneFast vs ggml.ai, quel outil AI Large Language Model (LLM) sort en tête? Nous comparons les avis, les prix, les alternatives, les votes positifs, les fonctionnalités, et plus encore.
Entre FinetuneFast et ggml.ai, lequel est supérieur?
En comparant FinetuneFast avec ggml.ai, qui sont tous deux des outils large language model (llm) alimentés par l'IA, Les utilisateurs ont clairement exprimé leur préférence, FinetuneFast mène en termes de votes positifs. Le nombre de votes positifs pour FinetuneFast est de 8, et pour ggml.ai il est de 6.
Vous pensez que nous avons tort? Votez et montrez-nous qui est le patron!
FinetuneFast


Qu'est-ce que FinetuneFast?
FinetuneFast est un kit de base payant pour l'affinage et le déploiement de modèles d'apprentissage automatique. Il regroupe des scripts d'entraînement pré-configurés, des pipelines de chargement de données, une optimisation des hyperparamètres, ainsi que des modèles de déploiement, permettant aux développeurs de passer rapidement de la mise en place à la production, sans tout construire from scratch.
Le package couvre la génération de texte en image, les grands modèles de langage, les applications RAG et les workflows associés. Les exemples inclus font référence à des fournisseurs tels qu'AWS Bedrock, Mistral AI, et OpenAI, ainsi que des modèles pour Flux-Schnell de texte à image, Fish-Speech pour synthèse vocale, et la génération augmentée par récupération.
Après achat, les acheteurs ont accès aux matériaux du dépôt GitHub avec la documentation. Le plan All In inclut l'accès à la communauté Discord et des mises à jour à vie. Le fondateur Patrick a créé le produit à partir d'une expérience pratique en ingénierie ML, incluant le travail sur l'entraînement de modèles, les API d'inférence, et les infrastructures évolutives.
ggml.ai
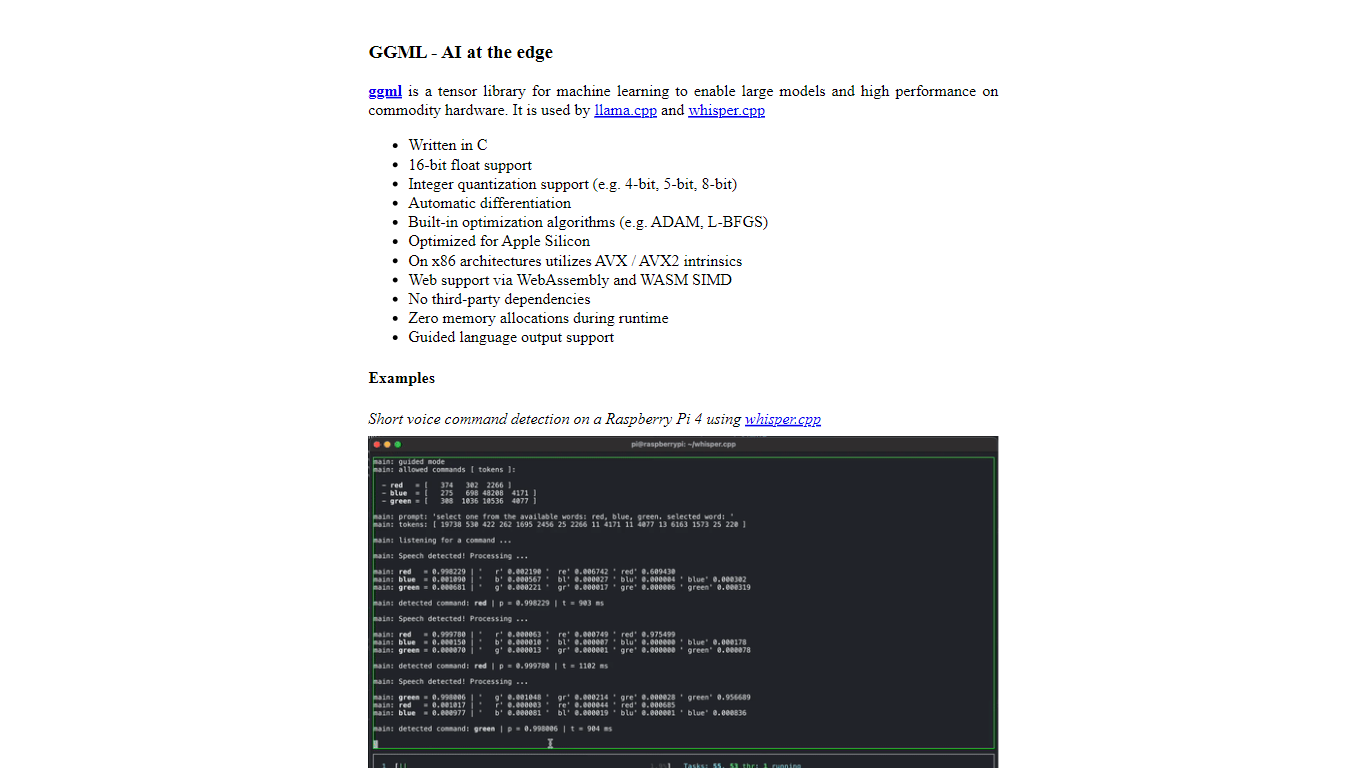
Qu'est-ce que ggml.ai?
ggml.ai est à la pointe de la technologie de l'IA, apportant de puissantes capacités d'apprentissage automatique directement à la périphérie grâce à sa bibliothèque de tenseurs innovante. Conçu pour la prise en charge de grands modèles et des performances élevées sur les plates-formes matérielles courantes, ggml.ai permet aux développeurs d'implémenter des algorithmes d'IA avancés sans avoir besoin d'équipement spécialisé. La plate-forme, écrite dans le langage de programmation C efficace, offre une prise en charge de la quantification flottante et entière 16 bits, ainsi que la différenciation automatique et divers algorithmes d'optimisation intégrés comme ADAM et L-BFGS. Il offre des performances optimisées pour Apple Silicon et exploite les intrinsèques AVX/AVX2 sur les architectures x86. Les applications basées sur le Web peuvent également exploiter ses capacités via la prise en charge de WebAssembly et WASM SIMD. Avec ses allocations de mémoire d'exécution nulles et son absence de dépendances tierces, ggml.ai présente une solution minimale et efficace pour l'inférence sur l'appareil.
Des projets tels que Whisper.cpp et Llama.cpp démontrent les capacités d'inférence hautes performances de ggml.ai, Whisper.cpp fournissant des solutions de synthèse vocale et Llama.cpp se concentrant sur l'inférence efficace du grand modèle de langage LLaMA de Meta. De plus, la société accueille favorablement les contributions à sa base de code et prend en charge un modèle de développement open-core via la licence MIT. Alors que ggml.ai continue de se développer, il recherche des développeurs à temps plein talentueux partageant une vision commune de l'inférence sur appareil pour rejoindre son équipe.
Conçu pour repousser les limites de l'IA à la pointe, ggml.ai témoigne de l'esprit de jeu et d'innovation de la communauté de l'IA.
FinetuneFast Votes positifs
ggml.ai Votes positifs
FinetuneFast Fonctionnalités principales
Scripts d'entraînement pré-configurés avec prise en charge multi-GPU et options de fine-tuning sans code
Pipelines efficaces de chargement de données pour préparer et organiser les jeux de données d'entraînement
Outils d'optimisation d'hyperparamètres pour ajuster la performance du modèle
Déploiement en un clic avec infrastructure auto-scalable et points d'API générés
Boilerplates d'inférence prêts pour la production, exemples RAG et templates de démarrage IA SaaS
Couverture des modèles incluant Flux-Schnell, Mistral, intégrations OpenAI, Fish-Speech TTS et workflows RAG
ggml.ai Fonctionnalités principales
Écrit en C : Garantit des performances élevées et une compatibilité sur une gamme de plates-formes.
Optimisation pour Apple Silicon : Offre un traitement efficace et une latence réduite sur les appareils Apple.
Prise en charge de WebAssembly et WASM SIMD : Facilite l'utilisation des applications Web par les capacités d'apprentissage automatique.
Aucune dépendance tierce : Permet une base de code épurée et un déploiement pratique.
Prise en charge de la sortie linguistique guidée : Améliore l'interaction homme-machine avec des réponses plus intuitives générées par l'IA.
FinetuneFast Catégorie
- Large Language Model (LLM)
ggml.ai Catégorie
- Large Language Model (LLM)
FinetuneFast Type de tarification
- Paid
ggml.ai Type de tarification
- Freemium