Pickles vs Deep Voice 3
Lors de la comparaison de Pickles vs Deep Voice 3, quel outil AI Text to Speech (TTS) brille le plus? Nous examinons les prix, les alternatives, les votes positifs, les fonctionnalités, les avis, et bien plus.
Entre Pickles et Deep Voice 3, lequel est supérieur?
Quand nous mettons Pickles et Deep Voice 3 côte à côte, tous deux étant des outils text to speech (tts) alimentés par l'IA, Les deux outils ont reçu le même nombre de votes positifs des utilisateurs de aitools.fyi. Le pouvoir est entre vos mains ! Votez et participez à la décision du gagnant.
Vous pensez que nous avons tort? Votez et montrez-nous qui est le patron!
Pickles
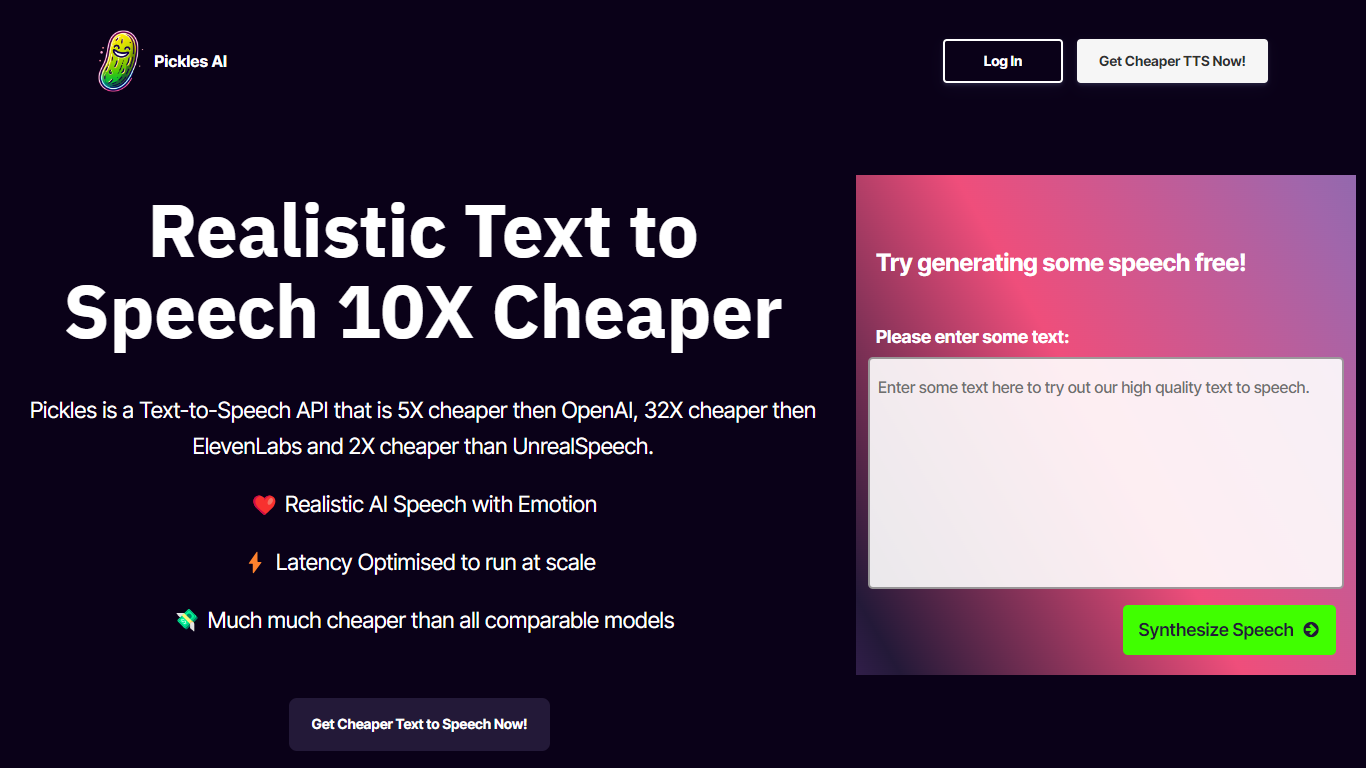

Qu'est-ce que Pickles?
Pickles AI propose une API révolutionnaire de synthèse vocale (TTS) conçue pour fournir une parole d'IA réaliste et de haute qualité avec émotion, tout en étant nettement plus rentable que ses concurrents.
Il offre des performances de latence optimisées d'environ 500 ms, garantissant des réponses rapides, idéales pour la mise à l'échelle des applications. Le service TTS de Pickles se distingue non seulement par son prix jusqu'à 32 fois moins cher que ses concurrents comme ElevenLabs, mais également par son intégration transparente qui ne nécessite qu'un simple appel HTTPS.
Les utilisateurs et développeurs intéressés peuvent s'abonner pour obtenir leur clé API et choisir parmi des forfaits flexibles en fonction de leurs besoins, du niveau hobby à l'échelle de l'entreprise. Avec la promesse de ne pas avoir de listes d'attente et d'une simple inscription, Pickles AI rend les discours puissants et émotionnels accessibles à un public plus large.
Deep Voice 3
Qu'est-ce que Deep Voice 3?
Deep Voice 3 est un système de synthèse vocale open source qui utilise un réseau de neurones entièrement convolutionnel pour transformer du texte en parole naturelle. Il prend en charge à la fois des modèles mono-voix et multi-voix, permettant de générer des voix variées et avec différents accents. Le système est conçu pour évoluer efficacement, gérer de grands ensembles de données et s'entraîner rapidement par rapport aux modèles TTS traditionnels.
L'architecture comprend un encodeur qui traite les entrées textuelles, un décodeur basé sur l'attention qui prédit des spectrogrammes de type mel, et un réseau de conversion qui génère les paramètres du vocodeur pour la synthèse de la forme d'onde. Cette conception contribue à produire une parole claire et naturelle avec moins de fautes de prononciation. Deep Voice 3 supporte également l'entraînement sur des entrées phonèmes, caractères ou mixtes, ce qui améliore la précision de la prononciation.
Des implémentations récentes ont démontré la capacité du modèle à synthétiser la parole à partir de plusieurs locuteurs avec des accents et des âges distincts, montrant ainsi sa polyvalence. Des échantillons audio issus d'accents anglais variés, notamment du sud de l'Angleterre et écossais, mettent en évidence son adaptabilité à différents styles de parole.
Deep Voice 3 convient aux développeurs et chercheurs souhaitant créer des applications TTS évolutives et de haute qualité. Sa nature open source permet la personnalisation et l’expérimentation avec différents réglages de modèles et ensembles de données.
Bien que la technologie de base reste conforme à la conception originale, des efforts communautaires en cours visent à améliorer l'efficacité de l'entraînement et à étendre les capacités multi-voix. La structure modulaire du système facilite l'intégration avec d’autres outils de traitement de la parole et vocodeurs.
Dans l’ensemble, Deep Voice 3 offre un bon équilibre entre vitesse, évolutivité et qualité de la parole, en faisant une ressource précieuse pour ceux qui travaillent sur des projets de synthèse vocale nécessitant flexibilité en termes de voix et de langues.
Pour des insights techniques détaillés et des guides de mise en œuvre, le document de recherche original et les dépôts open source offrent des ressources complètes.
Pickles Votes positifs
Deep Voice 3 Votes positifs
Pickles Fonctionnalités principales
Efficacité des coûts : Offre une API TTS nettement moins chère que celle des concurrents.
Réalisme : Fournit un discours d'IA réaliste qui transmet des émotions.
Latence optimisée : Garantit une faible latence (~ 500 ms) pour des performances fluides à grande échelle.
Facilité d'intégration : Conçu pour une intégration simple avec un seul appel HTTPS.
Forfaits flexibles : Répond à différents besoins d'utilisation avec différents plans d'abonnement.
Deep Voice 3 Fonctionnalités principales
🎤 Prise en charge multi-voix avec des accents et des âges variés pour une diversité vocale
⚡ Vitesses d'entraînement rapides permettant un développement plus rapide du modèle
🧩 Options d'entrée flexibles utilisant des phonèmes, des caractères, ou les deux pour une meilleure prononciation
🔊 Génère des spectrogrammes à échelle mel pour une synthèse audio de haute qualité
🔧 Code source ouvert permettant la personnalisation et l'intégration
Pickles Catégorie
- Text to Speech (TTS)
Deep Voice 3 Catégorie
- Text to Speech (TTS)
Pickles Type de tarification
- Freemium
Deep Voice 3 Type de tarification
- Freemium