
Last updated 10-23-2025
Category:
Reviews:
Join thousands of AI enthusiasts in the World of AI!
OmniHuman-1
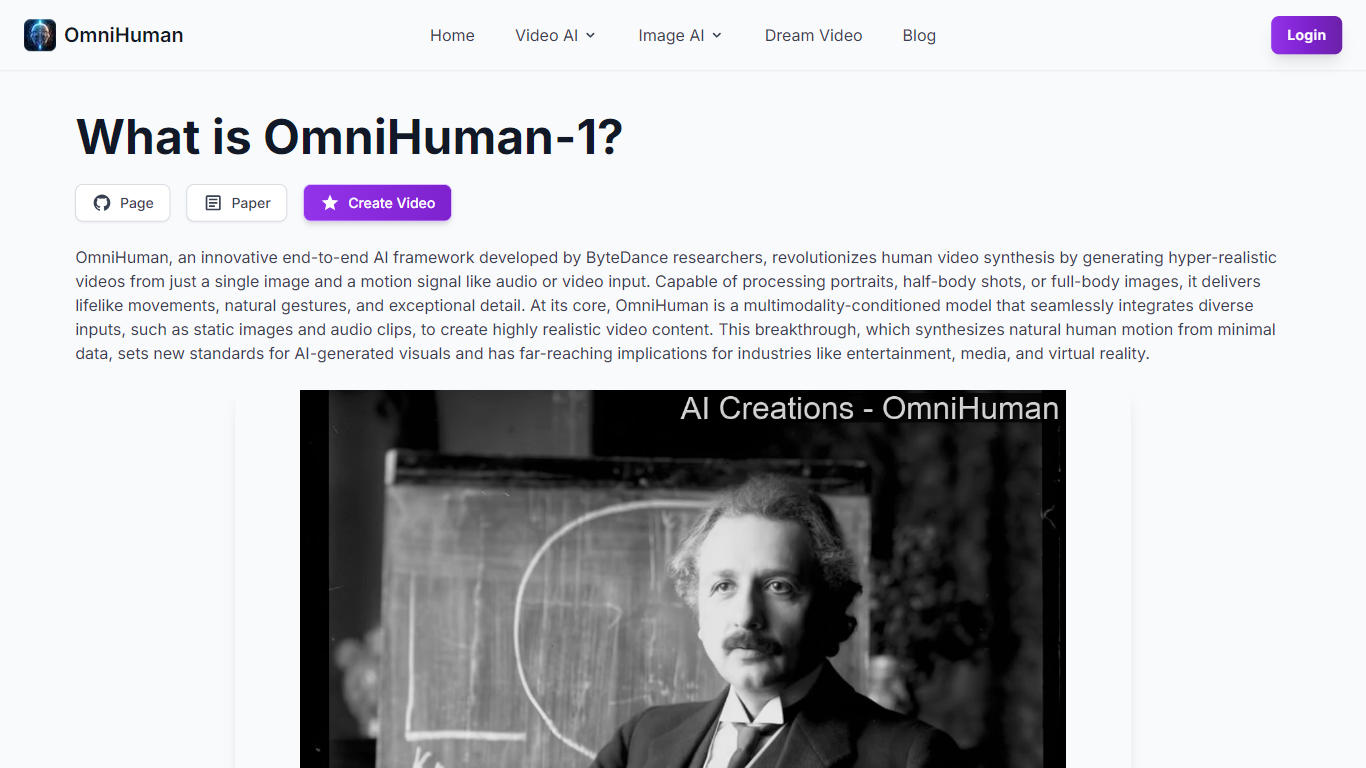
OmniHuman is an innovative end-to-end AI framework developed by ByteDance researchers, revolutionizing human video synthesis by generating hyper-realistic videos from just a single image and a motion signal like audio or video input. Capable of processing portraits, half-body shots, or full-body images, it delivers lifelike movements, natural gestures, and exceptional detail. At its core, OmniHuman is a multimodality-conditioned model that seamlessly integrates diverse inputs, such as static images and audio clips, to create highly realistic video content. This breakthrough, which synthesizes natural human motion from minimal data, sets new standards for AI-generated visuals and has far-reaching implications for industries like entertainment, media, and virtual reality. OmniHuman introduces a multimodal motion conditioning mixed training strategy, which allows the model to benefit from the scalability of mixed-condition data. This approach effectively addresses the challenges faced by previous end-to-end methods due to the limited availability of high-quality data. OmniHuman significantly outperforms existing methods, especially in generating highly realistic human videos from weak signal inputs, such as audio. The technology is adaptable to various industries, including entertainment, virtual reality, gaming, and media production, offering broad potential use cases. Leveraging advanced AI algorithms, OmniHuman represents a significant leap forward in human video synthesis, setting new benchmarks for realism and performance.
Single-Image to Video Generation: Create realistic human videos using just one image, making it easy to generate content without needing complex datasets.
Multimodal Input Support: Combine images and audio clips to produce synchronized videos, enhancing the storytelling experience.
Versatile Image Compatibility: Process various image types, including portraits and full-body shots, with consistent quality and realism.
Natural Motion Synthesis: Generate fluid movements and gestures that capture subtle details, making videos appear lifelike.
High Attention to Detail: Render intricate features like facial expressions and body language, ensuring videos are strikingly realistic.
What is the difference between OmniHuman-1 and other human video generation models?
OmniHuman-1 can generate human videos from a single image and various motion signals, like audio or video. It uses a unique training strategy that helps it work better with mixed-condition data.
How does OmniHuman-1 handle different types of input images?
OmniHuman-1 can process portraits, half-body shots, and full-body images. It maintains consistent quality and realism across all image types.
What are the limitations of OmniHuman-1?
OmniHuman-1 may struggle with complex scenes or detailed environments. It also needs a high-quality reference image to produce good results.
How can I use OmniHuman-1 in my projects?
You can use OmniHuman-1 for various applications like movies, TV shows, and games. Just upload your image and motion signal to get started.
What are the ethical considerations when using OmniHuman-1?
It's important to think about the ethical implications of AI-generated content. Ensure that the videos created are appropriate and respectful.
Can I create videos of animated characters with OmniHuman-1?
Yes, OmniHuman-1 can animate not just humans but also cartoons and animals, making it versatile for different types of content.
What industries can benefit from using OmniHuman-1?
OmniHuman-1 is useful in entertainment, virtual reality, gaming, and media production, offering many potential applications.