FinetuneFast vs ggml.ai
In the battle of FinetuneFast vs ggml.ai, which AI Large Language Model (LLM) tool comes out on top? We compare reviews, pricing, alternatives, upvotes, features, and more.
Between FinetuneFast and ggml.ai, which one is superior?
Upon comparing FinetuneFast with ggml.ai, which are both AI-powered large language model (llm) tools, The users have made their preference clear, FinetuneFast leads in upvotes. The number of upvotes for FinetuneFast stands at 8, and for ggml.ai it's 6.
Think we got it wrong? Cast your vote and show us who's boss!
FinetuneFast


What is FinetuneFast?
FinetuneFast is a paid boilerplate kit for fine-tuning and deploying machine learning models. It bundles pre-configured training scripts, data loading pipelines, hyperparameter optimization, and deployment templates so developers can move from setup to production faster than building everything from scratch.
The package covers text-to-image, large language models, RAG applications, and related workflows. Included examples reference providers such as AWS Bedrock, Mistral AI, and OpenAI, along with templates for Flux-Schnell text-to-image, Fish-Speech text-to-speech, and retrieval-augmented generation.
After purchase, buyers receive access to GitHub repository materials with documentation. The All In plan adds Discord community access and lifetime updates. Founder Patrick built the product from hands-on ML engineering experience, including work on model training, inference APIs, and scalable infrastructure.
ggml.ai
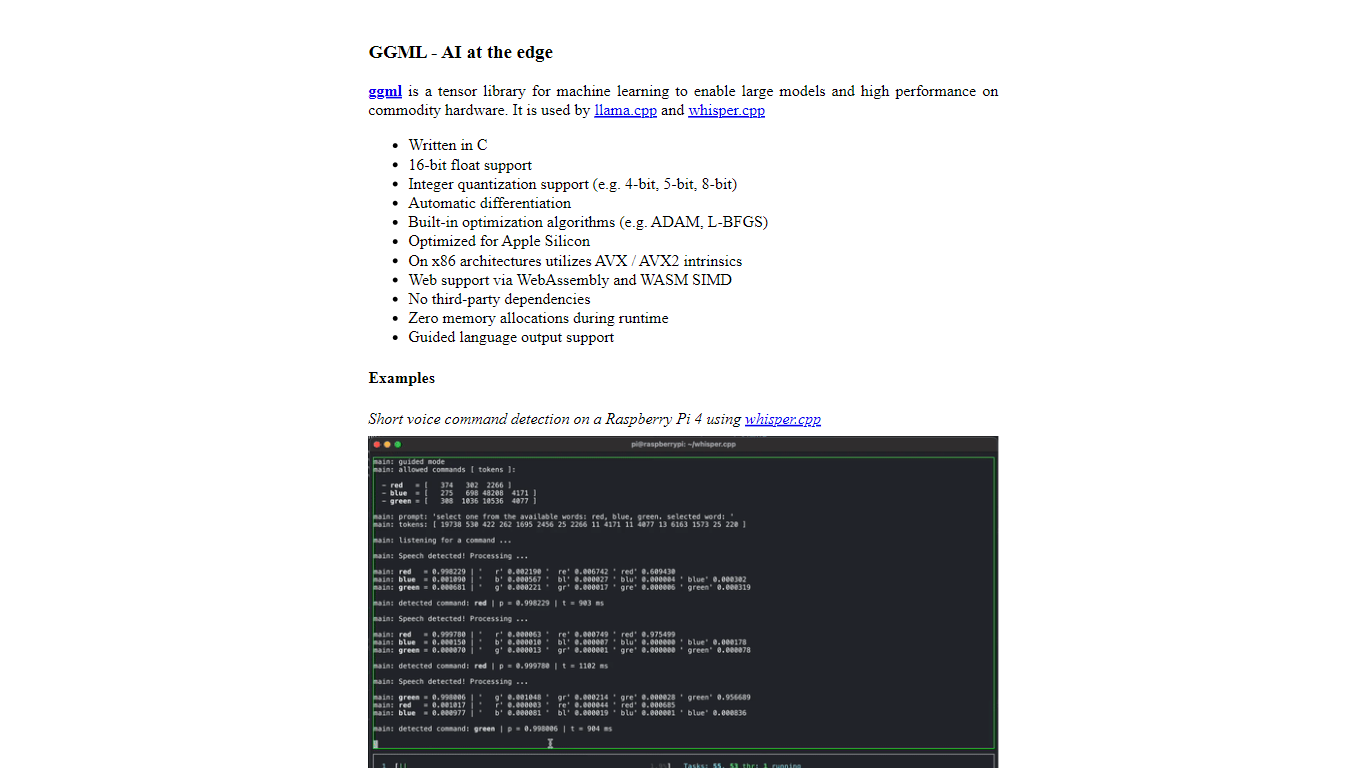
What is ggml.ai?
ggml.ai is at the forefront of AI technology, bringing powerful machine learning capabilities directly to the edge with its innovative tensor library. Built for large model support and high performance on common hardware platforms, ggml.ai enables developers to implement advanced AI algorithms without the need for specialized equipment. The platform, written in the efficient C programming language, offers 16-bit float and integer quantization support, along with automatic differentiation and various built-in optimization algorithms like ADAM and L-BFGS. It boasts optimized performance for Apple Silicon and leverages AVX/AVX2 intrinsics on x86 architectures. Web-based applications can also exploit its capabilities via WebAssembly and WASM SIMD support. With its zero runtime memory allocations and absence of third-party dependencies, ggml.ai presents a minimal and efficient solution for on-device inference.
Projects like whisper.cpp and llama.cpp demonstrate the high-performance inference capabilities of ggml.ai, with whisper.cpp providing speech-to-text solutions and llama.cpp focusing on efficient inference of Meta's LLaMA large language model. Moreover, the company welcomes contributions to its codebase and supports an open-core development model through the MIT license. As ggml.ai continues to expand, it seeks talented full-time developers with a shared vision for on-device inference to join their team.
Designed to push the envelope of AI at the edge, ggml.ai is a testament to the spirit of play and innovation in the AI community.
FinetuneFast Upvotes
ggml.ai Upvotes
FinetuneFast Top Features
Pre-configured training scripts with multi-GPU support and no-code fine-tuning options
Efficient data loading pipelines for preparing and organizing training datasets
Hyperparameter optimization tools to tune model performance
One-click deployment with auto-scaling infrastructure and generated API endpoints
Production-ready inference boilerplates, RAG examples, and AI SaaS starter templates
Model coverage includes Flux-Schnell, Mistral, OpenAI integrations, Fish-Speech TTS, and RAG workflows
ggml.ai Top Features
Written in C: Ensures high performance and compatibility across a range of platforms.
Optimization for Apple Silicon: Delivers efficient processing and lower latency on Apple devices.
Support for WebAssembly and WASM SIMD: Facilitates web applications to utilize machine learning capabilities.
No Third-Party Dependencies: Makes for an uncluttered codebase and convenient deployment.
Guided Language Output Support: Enhances human-computer interaction with more intuitive AI-generated responses.
FinetuneFast Category
- Large Language Model (LLM)
ggml.ai Category
- Large Language Model (LLM)
FinetuneFast Pricing Type
- Paid
ggml.ai Pricing Type
- Freemium