ttsMP3 vs Deep Voice 3
In the clash of ttsMP3 vs Deep Voice 3, which AI Text to Speech (TTS) tool emerges victorious? We assess reviews, pricing, alternatives, features, upvotes, and more.
When we put ttsMP3 and Deep Voice 3 head to head, which one emerges as the victor?
Let's take a closer look at ttsMP3 and Deep Voice 3, both of which are AI-driven text to speech (tts) tools, and see what sets them apart. Both tools are equally favored, as indicated by the identical upvote count. The power is in your hands! Cast your vote and have a say in deciding the winner.
Disagree with the result? Upvote your favorite tool and help it win!
ttsMP3
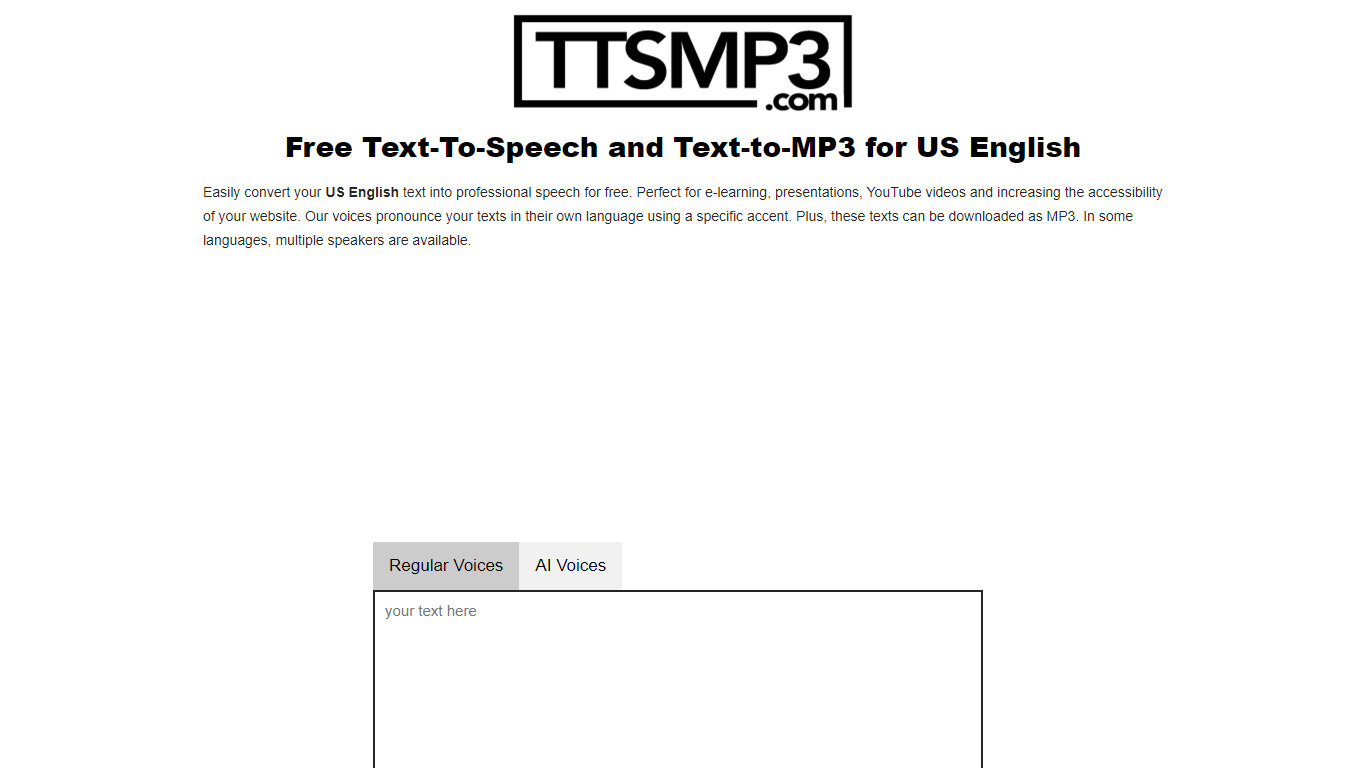

What is ttsMP3?
ttsMP3.com provides a straightforward way to convert text into natural-sounding speech in over 28 languages, including US English and many accents. It supports multiple speakers for some languages, making it useful for diverse content needs. Users can listen online or download the speech as MP3 files, which is handy for e-learning, presentations, YouTube videos, and improving website accessibility.
The platform offers simple controls to enhance speech output, such as adding breaks, emphasizing words, adjusting speed and pitch, and even whisper effects. These features help users create more engaging and customized audio content without needing technical expertise.
Powered by Amazon Polly, ttsMP3 leverages reliable speech synthesis technology to deliver clear and professional voices. The service is free with daily limits, and users can register for premium access to convert larger amounts of text.
The interface is user-friendly, allowing quick text input up to 3,000 characters per day for free users. It also supports SSML tags for advanced customization if users want to dive deeper into speech effects.
This tool is ideal for educators, content creators, and website owners who want to add voice content quickly without complex setups. It balances ease of use with enough options to tailor speech output to specific needs.
Overall, ttsMP3 remains a reliable and accessible text-to-speech service with a broad language range and useful voice customization features, making it a practical choice for many audio content projects.
Deep Voice 3
What is Deep Voice 3?
Deep Voice 3 is an open source text-to-speech system that uses a fully convolutional neural network to convert text into natural-sounding speech. It supports both single-speaker and multi-speaker models, allowing it to generate speech in various voices and accents. The system is designed to scale efficiently, handling large datasets and training quickly compared to traditional TTS models.
The architecture includes an encoder that processes text inputs, an attention-based decoder that predicts mel-scale spectrograms, and a converter network that generates vocoder parameters for waveform synthesis. This design helps produce clear and natural speech with fewer mispronunciations. Deep Voice 3 also supports training on phoneme, character, or mixed inputs, which improves pronunciation accuracy.
Recent implementations have demonstrated the model's ability to synthesize speech from multiple speakers with distinct accents and ages, showcasing its versatility. Audio samples from various English accents, including Southern England and Scottish, highlight its adaptability to different speech styles.
Deep Voice 3 is suitable for developers and researchers interested in building scalable, high-quality TTS applications. Its open source nature allows customization and experimentation with different model configurations and datasets.
While the core technology remains consistent with the original design, ongoing community efforts focus on improving training efficiency and expanding multi-speaker capabilities. The system's modular structure facilitates integration with other speech processing tools and vocoders.
Overall, Deep Voice 3 offers a balance of speed, scalability, and speech quality, making it a valuable resource for those working on speech synthesis projects that require flexibility across voices and languages.
For detailed technical insights and implementation guidance, the original research paper and open source repositories provide comprehensive resources.
ttsMP3 Upvotes
Deep Voice 3 Upvotes
ttsMP3 Top Features
🎙️ Supports 28+ languages with multiple accents for diverse needs
💾 Download generated speech as MP3 files for offline use
⚙️ Customize speech with breaks, emphasis, speed, pitch, and whisper effects
🔊 Listen to speech online before downloading for quick review
🔐 Premium access available for higher daily text limits and extended use
Deep Voice 3 Top Features
🎤 Multi-speaker support with varied accents and ages for diverse voices
⚡ Fast training speeds enabling quicker model development
🧩 Flexible input options using phonemes, characters, or both for better pronunciation
🔊 Generates mel-scale spectrograms for high-quality audio synthesis
🔧 Open source codebase allowing customization and integration
ttsMP3 Category
- Text to Speech (TTS)
Deep Voice 3 Category
- Text to Speech (TTS)
ttsMP3 Pricing Type
- Freemium
Deep Voice 3 Pricing Type
- Freemium