Voice to Text vs Deep Voice 3
Explore the showdown between Voice to Text vs Deep Voice 3 and find out which AI Text to Speech (TTS) tool wins. We analyze upvotes, features, reviews, pricing, alternatives, and more.
In a face-off between Voice to Text and Deep Voice 3, which one takes the crown?
When we contrast Voice to Text with Deep Voice 3, both of which are exceptional AI-operated text to speech (tts) tools, and place them side by side, we can spot several crucial similarities and divergences. There's no clear winner in terms of upvotes, as both tools have received the same number. The power is in your hands! Cast your vote and have a say in deciding the winner.
Disagree with the result? Upvote your favorite tool and help it win!
Voice to Text
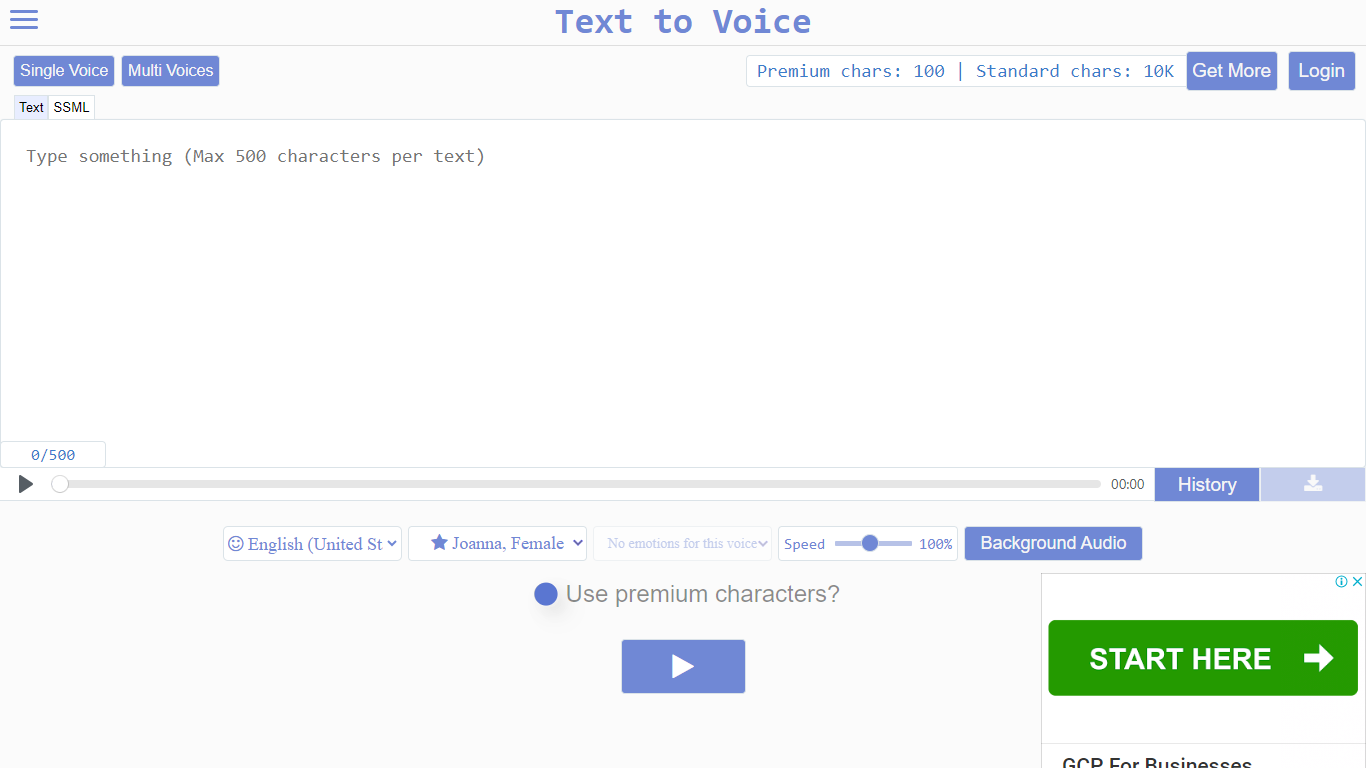

What is Voice to Text?
Voice to Text offers a free online English text to speech converter that transforms written text into natural, human-like spoken words. It supports a wide range of emotions, allowing users to add feelings like joy, anger, or surprise to their voiceovers. The tool features Generation 2 voices, which provide ultra-lifelike audio that changes tone with each playback, making repeated listening more engaging.
Users can easily select language, voice, speech style, and emotion before converting text, with the option to download the audio as an MP3 file. A premium voice option enhances realism by using an advanced algorithm, producing less robotic and more convincing speech. This premium feature requires premium characters, which users receive daily for free or can purchase additionally.
The platform is designed for various users including content creators, educators, marketers, and social media influencers who want professional narration for videos or presentations without recording their own voice. It works smoothly on both Mac OS and Windows through a web interface, ensuring accessibility across devices.
Security is a priority; generated audio files are stored temporarily with randomized IDs and deleted regularly to protect user privacy. All text-to-speech processing happens on the server side, ensuring fast performance without taxing the user's device.
The tool is especially useful for creating voiceovers for Instagram, TikTok, and other social media platforms, helping videos feel more professional and easier to understand. Its fast conversion speed and high audio quality make it a practical choice for anyone needing quick, realistic voice generation with emotional nuance.
Deep Voice 3
What is Deep Voice 3?
Deep Voice 3 is an open source text-to-speech system that uses a fully convolutional neural network to convert text into natural-sounding speech. It supports both single-speaker and multi-speaker models, allowing it to generate speech in various voices and accents. The system is designed to scale efficiently, handling large datasets and training quickly compared to traditional TTS models.
The architecture includes an encoder that processes text inputs, an attention-based decoder that predicts mel-scale spectrograms, and a converter network that generates vocoder parameters for waveform synthesis. This design helps produce clear and natural speech with fewer mispronunciations. Deep Voice 3 also supports training on phoneme, character, or mixed inputs, which improves pronunciation accuracy.
Recent implementations have demonstrated the model's ability to synthesize speech from multiple speakers with distinct accents and ages, showcasing its versatility. Audio samples from various English accents, including Southern England and Scottish, highlight its adaptability to different speech styles.
Deep Voice 3 is suitable for developers and researchers interested in building scalable, high-quality TTS applications. Its open source nature allows customization and experimentation with different model configurations and datasets.
While the core technology remains consistent with the original design, ongoing community efforts focus on improving training efficiency and expanding multi-speaker capabilities. The system's modular structure facilitates integration with other speech processing tools and vocoders.
Overall, Deep Voice 3 offers a balance of speed, scalability, and speech quality, making it a valuable resource for those working on speech synthesis projects that require flexibility across voices and languages.
For detailed technical insights and implementation guidance, the original research paper and open source repositories provide comprehensive resources.
Voice to Text Upvotes
Deep Voice 3 Upvotes
Voice to Text Top Features
🎭 Emotional Speech Styles: Add feelings like joy or anger to voices for expressive narration.
🎧 Gen2 Voices: Experience ultra-realistic voices that vary tone with each playback.
💾 Free MP3 Downloads: Save your generated voiceovers instantly without extra cost.
⚡ Fast Conversion: Get voice output in seconds, even with slower internet connections.
🔒 Secure Processing: Audio files are temporarily stored with random IDs and deleted regularly.
Deep Voice 3 Top Features
🎤 Multi-speaker support with varied accents and ages for diverse voices
⚡ Fast training speeds enabling quicker model development
🧩 Flexible input options using phonemes, characters, or both for better pronunciation
🔊 Generates mel-scale spectrograms for high-quality audio synthesis
🔧 Open source codebase allowing customization and integration
Voice to Text Category
- Text to Speech (TTS)
Deep Voice 3 Category
- Text to Speech (TTS)
Voice to Text Pricing Type
- Freemium
Deep Voice 3 Pricing Type
- Freemium