ggml.ai vs Mystic
Lors de la comparaison de ggml.ai vs Mystic, quel outil AI Large Language Model (LLM) brille le plus? Nous examinons les prix, les alternatives, les votes positifs, les fonctionnalités, les avis, et bien plus.
Dans une comparaison entre ggml.ai et Mystic, lequel sort vainqueur?
Quand nous mettons ggml.ai et Mystic côte à côte, tous deux étant des outils large language model (llm) alimentés par l'IA, Le décompte des votes positifs est au coude à coude pour ggml.ai et Mystic. Rejoignez les utilisateurs de aitools.fyi pour décider du gagnant en votant.
Pas votre tasse de thé? Votez pour votre outil préféré et remuez les choses!
ggml.ai
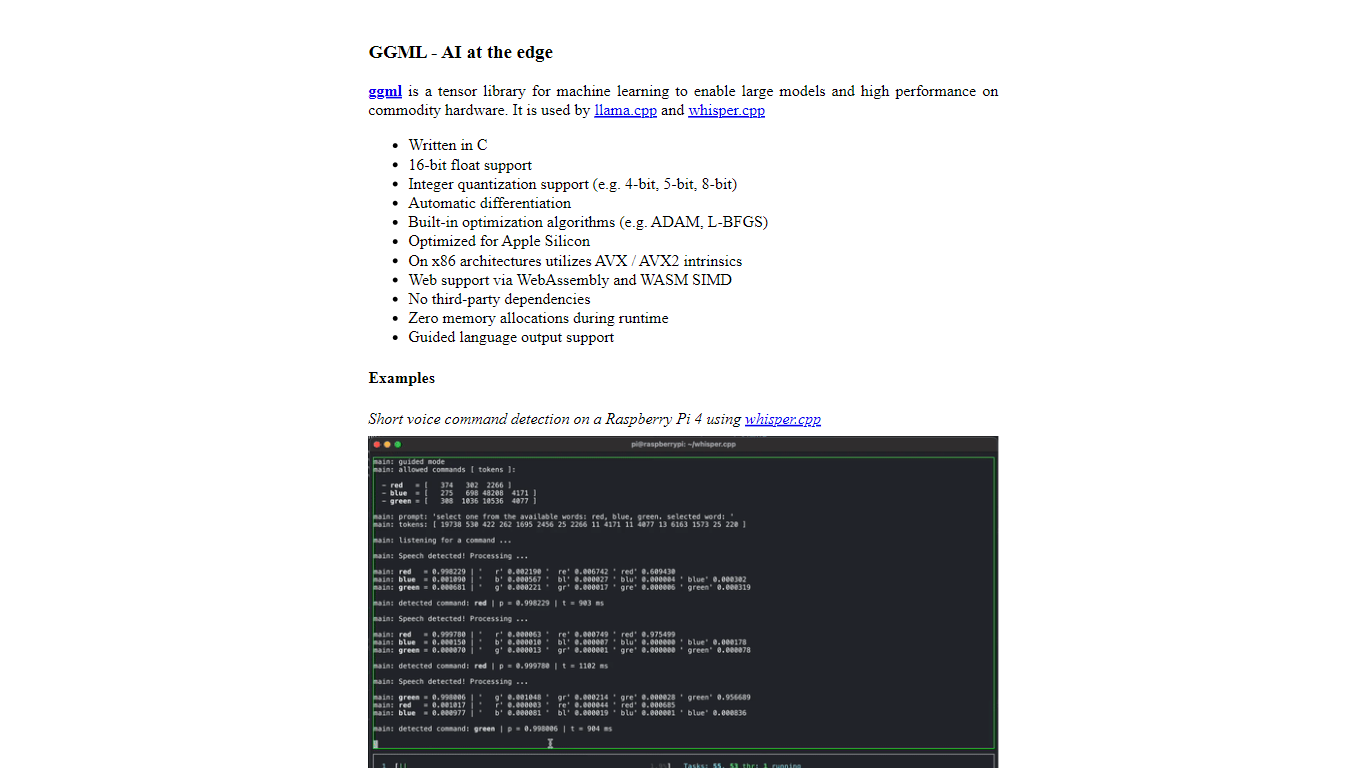

Qu'est-ce que ggml.ai?
ggml.ai est à la pointe de la technologie de l'IA, apportant de puissantes capacités d'apprentissage automatique directement à la périphérie grâce à sa bibliothèque de tenseurs innovante. Conçu pour la prise en charge de grands modèles et des performances élevées sur les plates-formes matérielles courantes, ggml.ai permet aux développeurs d'implémenter des algorithmes d'IA avancés sans avoir besoin d'équipement spécialisé. La plate-forme, écrite dans le langage de programmation C efficace, offre une prise en charge de la quantification flottante et entière 16 bits, ainsi que la différenciation automatique et divers algorithmes d'optimisation intégrés comme ADAM et L-BFGS. Il offre des performances optimisées pour Apple Silicon et exploite les intrinsèques AVX/AVX2 sur les architectures x86. Les applications basées sur le Web peuvent également exploiter ses capacités via la prise en charge de WebAssembly et WASM SIMD. Avec ses allocations de mémoire d'exécution nulles et son absence de dépendances tierces, ggml.ai présente une solution minimale et efficace pour l'inférence sur l'appareil.
Des projets tels que Whisper.cpp et Llama.cpp démontrent les capacités d'inférence hautes performances de ggml.ai, Whisper.cpp fournissant des solutions de synthèse vocale et Llama.cpp se concentrant sur l'inférence efficace du grand modèle de langage LLaMA de Meta. De plus, la société accueille favorablement les contributions à sa base de code et prend en charge un modèle de développement open-core via la licence MIT. Alors que ggml.ai continue de se développer, il recherche des développeurs à temps plein talentueux partageant une vision commune de l'inférence sur appareil pour rejoindre son équipe.
Conçu pour repousser les limites de l'IA à la pointe, ggml.ai témoigne de l'esprit de jeu et d'innovation de la communauté de l'IA.
Mystic
Qu'est-ce que Mystic?
Recherchez-vous un moyen simple de déployer et de faire évoluer vos modèles de Machine Learning ? Cherchez pas plus loin! Notre site Web propose une solution de pointe pour un déploiement et une mise à l'échelle sans effort de modèles ML à l'aide de l'inférence GPU sans serveur. Grâce à nos GPU NVIDIA avancés et à notre technologie propriétaire, vous pouvez bénéficier d'un déploiement de modèles ultra-rapide comme jamais auparavant.
Dites adieu aux complexités du déploiement de modèles ML traditionnels. Notre plateforme est conçue pour rendre le processus transparent et convivial. Que vous soyez débutant ou data scientist expérimenté, vous trouverez nos outils intuitifs et faciles à utiliser. Nous comprenons que le temps presse, c'est pourquoi notre technologie vous permet de déployer et de faire évoluer vos modèles en toute simplicité.
Non seulement nous proposons un déploiement efficace, mais nous accordons également la priorité à l’évolutivité. Notre plateforme vous permet de faire évoluer vos modèles ML sans effort, en garantissant qu'ils peuvent gérer des charges de travail croissantes sans compromettre les performances. Que vous ayez besoin de gérer quelques requêtes ou un afflux massif de données, notre technologie peut tout gérer.
L'une des fonctionnalités clés de notre plateforme est l'utilisation de l'inférence GPU sans serveur. Cette technologie exploite la puissance des GPU NVIDIA avancés pour accélérer le processus d'inférence. En exploitant l’immense puissance de calcul des GPU, nous pouvons accélérer considérablement le déploiement et la mise à l’échelle des modèles ML. Cela signifie pour vous des informations plus rapides, des résultats plus rapides et une productivité améliorée.
Mais cela ne s'arrête pas là. Notre plateforme est équipée d'outils de pointe pour optimiser vos modèles ML pour une efficacité maximale. Nous fournissons une assistance complète pour l'optimisation des modèles, garantissant que vos modèles fonctionnent à leurs performances optimales. Qu'il s'agisse d'affiner les hyperparamètres, d'optimiser l'utilisation de la mémoire ou de réduire la latence, nous avons ce qu'il vous faut.
Prêt à essayer ? Inscrivez-vous maintenant et découvrez le déploiement et la mise à l'échelle transparents de vos modèles de Machine Learning. Notre plateforme est conçue pour responsabiliser les data scientists et les praticiens du ML de tous niveaux, ce qui rend plus facile que jamais la concrétisation de vos modèles. Profitez de notre technologie de pointe et libérez tout le potentiel de vos projets ML.
ggml.ai Votes positifs
Mystic Votes positifs
ggml.ai Fonctionnalités principales
Écrit en C : Garantit des performances élevées et une compatibilité sur une gamme de plates-formes.
Optimisation pour Apple Silicon : Offre un traitement efficace et une latence réduite sur les appareils Apple.
Prise en charge de WebAssembly et WASM SIMD : Facilite l'utilisation des applications Web par les capacités d'apprentissage automatique.
Aucune dépendance tierce : Permet une base de code épurée et un déploiement pratique.
Prise en charge de la sortie linguistique guidée : Améliore l'interaction homme-machine avec des réponses plus intuitives générées par l'IA.
Mystic Fonctionnalités principales
Aucune fonctionnalité principale répertoriéeggml.ai Catégorie
- Large Language Model (LLM)
Mystic Catégorie
- Large Language Model (LLM)
ggml.ai Type de tarification
- Freemium
Mystic Type de tarification
- Freemium