
Dernière mise à jour 10-31-2025
Catégorie:
Reviews:
Join thousands of AI enthusiasts in the World of AI!
WebcrawlerAPI
WebcrawlerAPI est un service simple d'exploration web et d'extraction de données conçu pour faciliter la collecte de contenu provenant de presque tous les sites web. Il offre une API simple qui renvoie un contenu de page propre et structuré, formaté pour des contextes de génération assistée par récupération (RAG) ou de modèles de langage de grande taille (LLM). Cela en fait une solution idéale pour les développeurs, data scientists et entreprises construisant des applications d'IA ou ayant besoin de données web fiables.
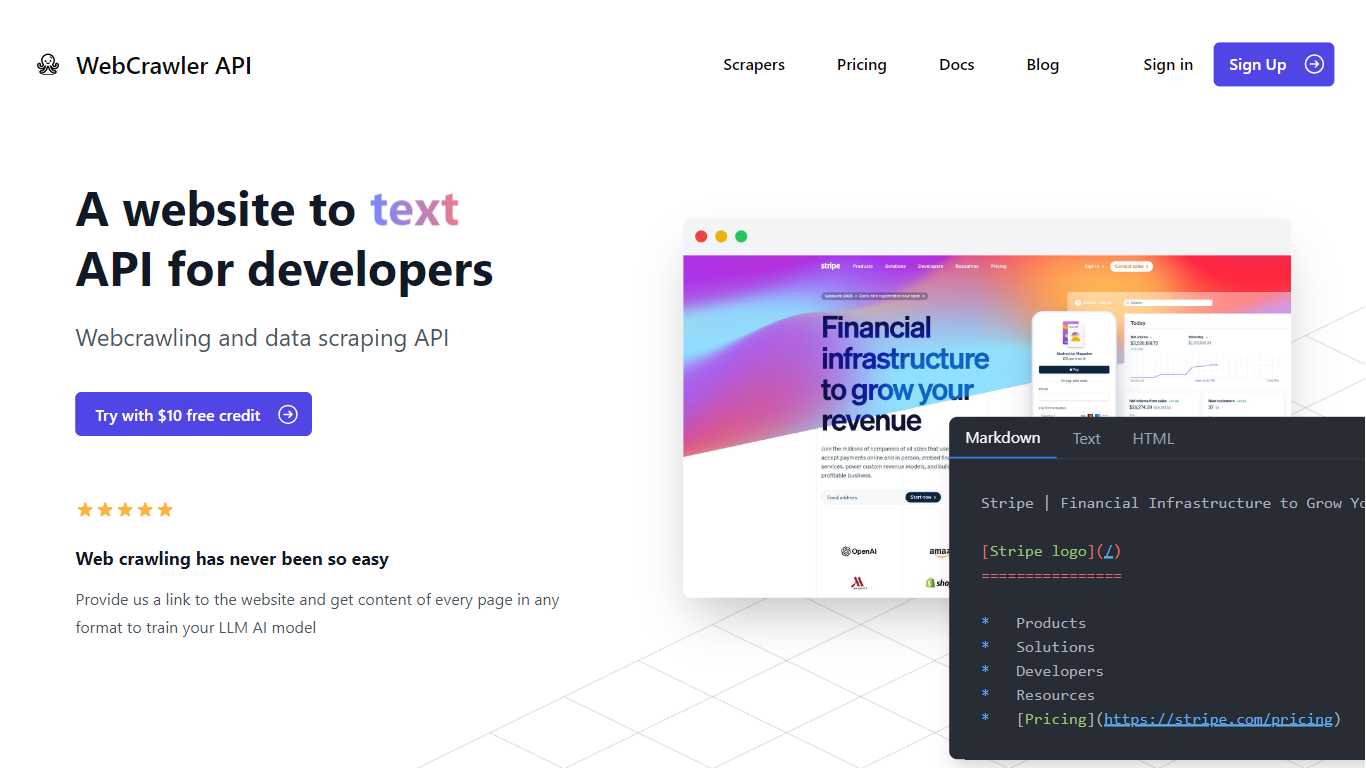
Le service gère tous les défis techniques en coulisses, notamment la gestion des proxies, des tentatives de retries, des navigateurs headless, des CAPTCHAs et des protections anti-bot. Cela signifie que les utilisateurs n'ont pas à se soucier des configurations complexes ou de la création de crawlers personnalisés. L'API se concentre sur la livraison d'un parsing précis du contenu, en extrayant le contenu principal au format Markdown ou texte brut.
WebcrawlerAPI supporte les intégrations sans code, permettant aux utilisateurs d'ajouter rapidement l'exploration web à leurs flux de travail sans écrire de code. Avec un taux de succès de 91 % et un temps moyen d'exploration d'environ 9 secondes, elle est à la fois fiable et efficace. Le modèle de tarification est simple et basé sur l'usage, sans abonnements ni frais cachés.
Le support est assuré par de vrais ingénieurs, pas par des chatbots, garantissant aux utilisateurs une assistance pratique en cas de besoin. Cet outil est particulièrement utile pour ceux qui travaillent sur des systèmes RAG ou entraînent des modèles d'IA, et qui ont besoin de contenus web propres et prêts à l'emploi. Son focus sur la facilité d'intégration et l'exploration prête pour la production le distingue de nombreux autres outils de scraping.
Dans l'ensemble, WebcrawlerAPI est un choix pratique pour quiconque a besoin d'une extraction de données web fiable, évolutive et précise, sans les tracas de la gestion de l'infrastructure sous-jacente ou des défis anti-bot.
📡 Un accès API facile pour délivrer le contenu web rapidement
🛠️ Gère automatiquement les proxies, les relances et les CAPTCHA
📄 Extrait le contenu principal de la page en Markdown ou en texte
⚙️ Intégrations sans code pour une configuration rapide sans programmation
👩💻 Support humain réel pour l’aide à l’intégration
Gère automatiquement des défis complexes de crawling comme les CAPTCHAs et les anti-bots
Fournit un contenu propre et structuré prêt pour les cas d'utilisation d'IA et RAG
Prend en charge l'intégration sans code pour une configuration facile sans programmation
Offre un support humain réel pour une résolution de problèmes plus rapide
Tarification simple au paiement à l'utilisation sans abonnement
Aucun niveau gratuit ni essai mentionné pour tester avant l'achat
Le temps moyen d'exploration est d'environ 9 secondes, ce qui peut être plus lent que certains concurrents
Puis-je explorer des pages spécifiques ou des sites web entiers avec WebcrawlerAPI ?
Oui, WebcrawlerAPI vous permet d'explorer des pages individuelles ou des sites web complets en fournissant les URL dont vous souhaitez extraire le contenu.
WebcrawlerAPI est-il adapté à la création de systèmes de génération augmentée par récupération (RAG) ?
Absolument. L'API retourne un contenu formaté pour des contextes RAG ou LLM, ce qui la rend idéale pour des applications d'IA nécessitant des données web propres et structurées.
Dois-je gérer les proxys ou les mesures anti-bot lors de l'utilisation de WebcrawlerAPI ?
Non, WebcrawlerAPI gère automatiquement les proxys, les nouvelles tentatives, les navigateurs sans interface utilisateur, les CAPTCHAs et les protections anti-bot, vous n'avez donc pas à vous en soucier.
Puis-je intégrer WebcrawlerAPI sans écrire de code ?
Oui, le service prend en charge les intégrations sans code, vous permettant d'ajouter facilement et rapidement l'exploration web à vos flux de travail.
Y a-t-il des frais d'abonnement pour utiliser WebcrawlerAPI ?
Non, WebcrawlerAPI utilise un modèle de tarification à l'utilisation sans abonnement ni frais cachés.
Quel type de support WebcrawlerAPI offre-t-il ?
Vous bénéficiez d'un support humain réel fourni par des ingénieurs, et non des chatbots, pour vous aider lors de l'intégration et en cas de problèmes.
Quelle est la rapidité du processus d'exploration avec WebcrawlerAPI ?
En moyenne, WebcrawlerAPI effectue une exploration en environ 9 secondes avec un taux de réussite de 91 %.