Apera AI 对比 Text-To-4D
在 Apera AI 和 Text-To-4D 的对决中,哪个 AI 3D Generation 工具脱颖而出?我们比较评论、定价、替代品、赞成票、功能等等。
Apera AI 和 Text-To-4D,哪一个更优?
当我们比较Apera AI和Text-To-4D时,这两个都是AI驱动的3d generation工具, 用户已经明确表示了他们的偏好,Text-To-4D在赞成票中领先。 Text-To-4D的赞成票数为 26,而 Apera AI 的赞成票数为 6。
感觉叛逆?投票并搅动事情!
Apera AI
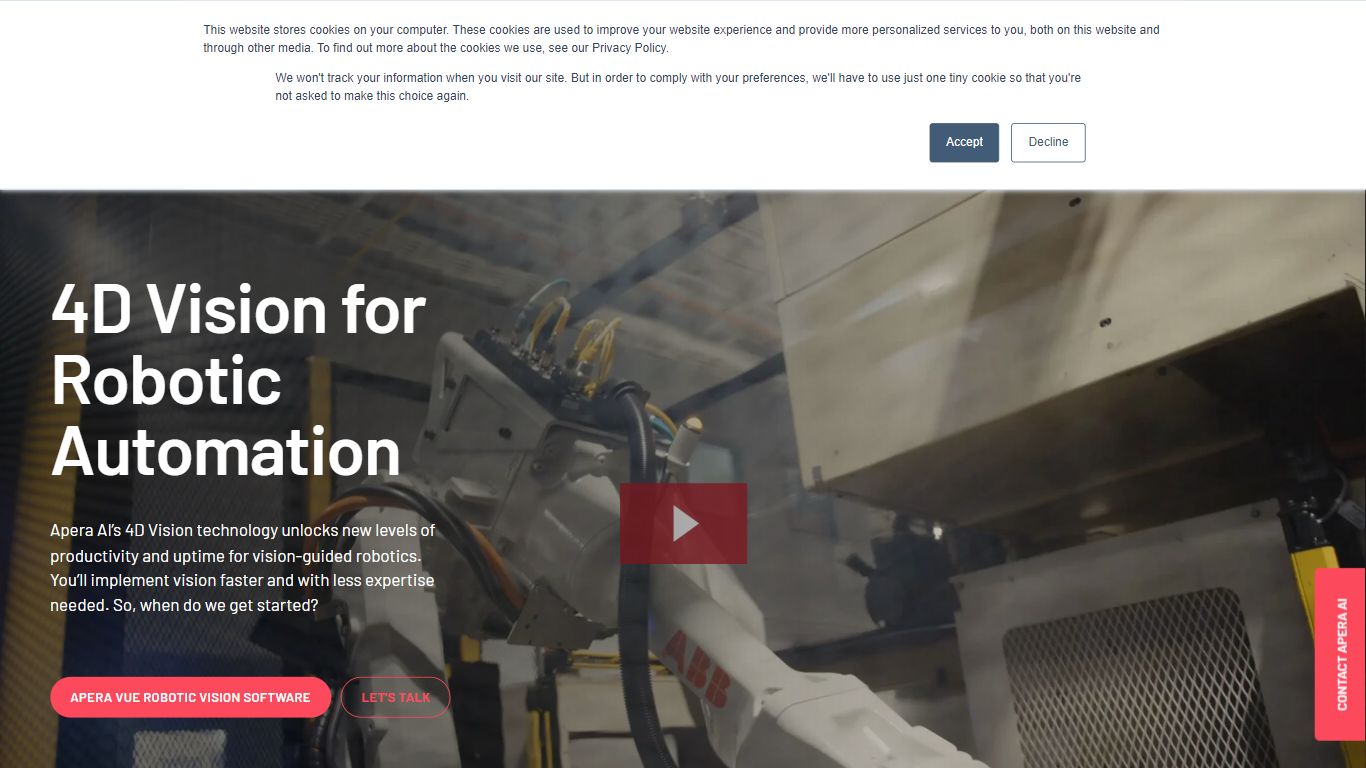

什么是 Apera AI?
Apera AI 利用其 4D 视觉技术和 Vue 机器人视觉软件,提升机器人自动化水平,提供更快速、更可靠的视觉引导机器人系统。该系统在复杂环境中表现出色,包括不同光照条件和复杂物体处理,适用于汽车、制造和物流等行业。Apera AI 的 Forge Lab 提供一个易于使用的 AI 训练和仿真平台,简化了部署流程,减少了对专业视觉技术的依赖。Vue 软件支持多个主要机器人品牌,利用 AI 在数百万次仿真周期中进行训练,达到最高 99.99%的可靠性,并实现循环时间低至 0.3 秒的快速机器人引导。其特色功能如 Autopilot 可以优化机器人路径,避免碰撞和奇异点,Dexterity 则提升双指夹持的精度。该解决方案适用于料箱拾取、机械手引出、装配、分类和包装等多种应用,能够适应不同类型和表面处理的物体。Apera AI 还强调使用现成的摄像头实现成本效益高的扩展,并提供即插即用的视觉程序,帮助加快项目进度、降低风险。领先的系统集成商和制造商在采用 Apera AI 技术后,报告在准确性、质量和生产效率方面取得了显著提升。
Text-To-4D

什么是 Text-To-4D?
Text-To-4D,也被称为 MAV3D(Make-A-Video3D),可以根据简单的文本描述生成三维动态场景。它利用一种为确保场景外观、一致性密度和运动优化的4D动态神经辐射场(NeRF),结合文本到视频的扩散模型实现。这使得创建可以从任何摄像机角度观看的动态视频成为可能,并能够集成到各种3D环境中。
不同于传统的3D生成方法,MAV3D不需要任何3D或4D的训练数据。它依赖于仅在文本-图像对和未标记视频上训练的文字到视频模型,使没有专门数据集的用户也能使用。这一方法为希望通过文本提示生成沉浸式3D动态内容的创作者、开发者和研究人员开启了新的可能性。
该工具面向广泛的用户群体,包括游戏开发者、动画师和虚拟现实内容创作人员,帮助他们无需手动建模或动画即可快速生成动态图景。它结合了文本驱动的生成与3D动态场景输出,具有独特的价值,可用于交互式应用或视觉叙事。
从技术上讲,该方法将4D NeRF与基于扩散的Text-to-Video模型集成,确保运动和外观在时间和空间上的一致性,从而生成平滑、逼真的动态场景,用户可以从多个角度进行探索。系统在之前的内部基础上取得了改进,能够根据文本输入生成更高质量、更连贯的3D视频。
整体而言,Text-To-4D作为首个能从文本生成完全动态3D场景的方法,弥补了文本视频生成与3D场景合成之间的差距,提供了一种灵活且创新的解决方案,用于创建沉浸式内容,无需复杂的3D数据或手动画面。
Apera AI 赞同数
Text-To-4D 赞同数
Apera AI 顶级功能
🚀 机器人快速引导,循环时间低至0.3秒,实现高吞吐量
🌗 视觉系统在各种光照条件下稳定工作,包括明亮、黑暗和户外环境
🤖 自动驾驶功能优化机器人路径,避免碰撞和关节问题
🎯 灵活性实现精准的双指抓取和物体方向控制
🧑🏫 Forge Lab 提供便捷的AI训练和仿真,加快部署速度
Text-To-4D 顶级功能
🎥 从文本提示生成动态3D视频,轻松创作内容
🌐 可从任意摄像角度查看生成的场景,自由探索环境
🛠️ 无需3D或4D训练数据,简化生成过程
⚙️ 结合4D神经辐射场和扩散模型,实现流畅运动
🔗 输出可集成到各种3D环境和应用中
Apera AI 类别
- 3D Generation
Text-To-4D 类别
- 3D Generation
Apera AI 定价类型
- Freemium
Text-To-4D 定价类型
- Free