Neuralangelo Research Reconstructs 3D Scenes | NVIDIA 对比 Text-To-4D
在 Neuralangelo Research Reconstructs 3D Scenes | NVIDIA 和 Text-To-4D 的对决中,哪个 AI 3D Generation 工具脱颖而出?我们比较评论、定价、替代品、赞成票、功能等等。
Neuralangelo Research Reconstructs 3D Scenes | NVIDIA 和 Text-To-4D,哪一个更优?
当我们比较Neuralangelo Research Reconstructs 3D Scenes | NVIDIA和Text-To-4D时,这两个都是AI驱动的3d generation工具, 在赞成票方面,Text-To-4D是首选。 Text-To-4D已经获得了 26 个赞成票,而 Neuralangelo Research Reconstructs 3D Scenes | NVIDIA 已经获得了 6 个赞成票。
认为我们错了?投票并向我们展示谁才是老大!
Neuralangelo Research Reconstructs 3D Scenes | NVIDIA

什么是 Neuralangelo Research Reconstructs 3D Scenes | NVIDIA?
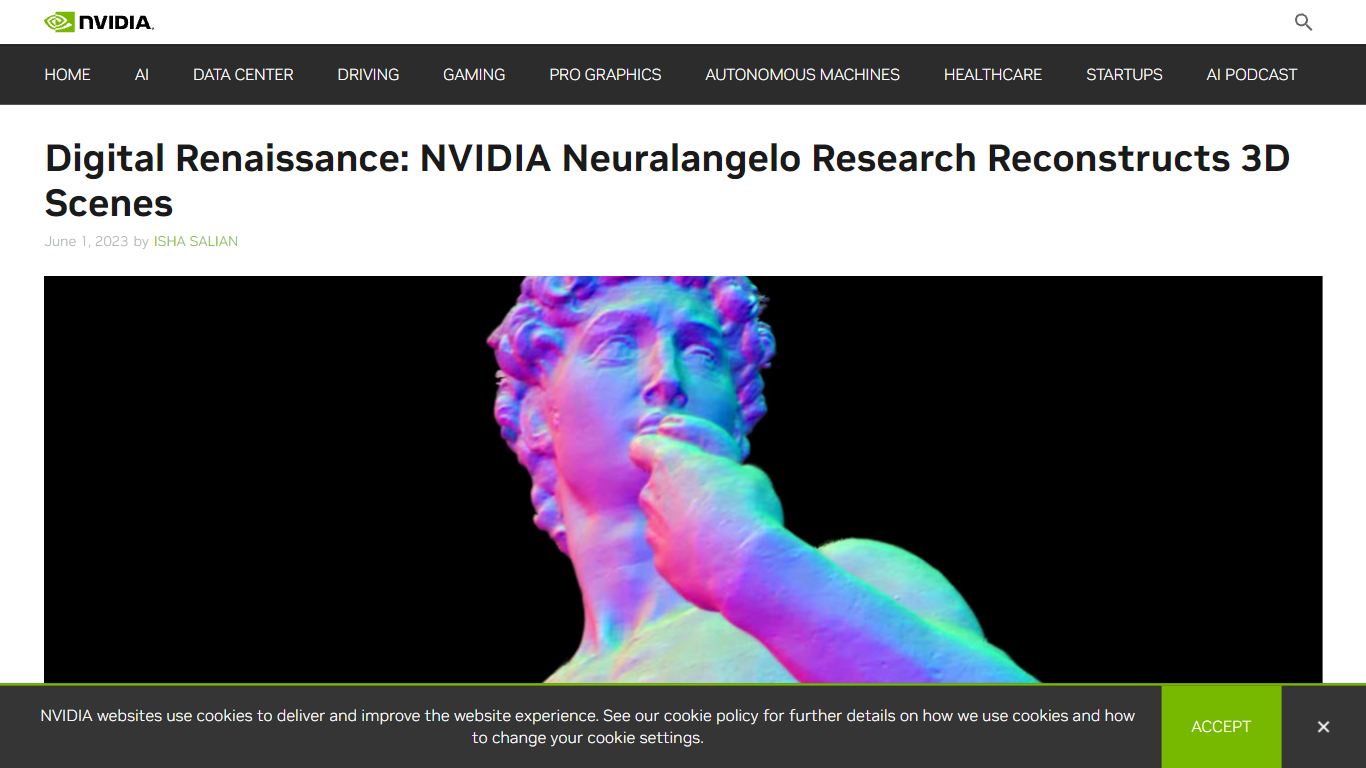
Neuralangelo 是由 NVIDIA 研究团队开发的一个人工智能模型,利用神经网络将二维视频片段转换为详细的三维结构。它可以创建逼真的虚拟物体复制品,如建筑、雕塑和复杂场景,捕捉多视角下的细节与纹理。这项技术面向虚拟现实、数字孪生、机器人和游戏开发等创意专业人士及开发者,帮助他们将高保真度的三维模型导入到设计流程中。
与早期方法不同,Neuralangelo 在复制复杂材质方面表现出色,如屋顶瓦片、玻璃幕墙和光滑的大理石表面,具有高度的准确性。它采用即时神经图形原语技术——即 NVIDIA Instant NeRF 的核心技术,捕捉先前难以实现的细节和重复纹理模式。该模型通过处理视频中的精选帧,估算相机位置,然后构建和优化三维模型,类似雕塑家从多个角度塑造对象的过程。
Neuralangelo 支持小型物体和大型场景的重建,包括建筑内部和外部场景,具体现了像米开朗基罗的大卫雕像和 NVIDIA 旧金山湾区园区的详细模型。这使其成为需要逼真数字复制品的行业中的多功能工具。
该模型简化了即使使用智能手机捕获素材也能创建可用虚拟资产的流程,加快了艺术家、设计师和工程师的工作进度。通过缩小物理世界与数字世界的差距,Neuralangelo 提升了娱乐、工业设计和机器人项目的逼真度和效率。
NVIDIA 已在 GitHub 上提供了 Neuralangelo,鼓励开发者和研究人员探索和基于此技术开发创新。它代表了三维重建技术的重要进步,将先进的神经渲染与广泛实际应用相结合,具有广泛的潜在用途。
Text-To-4D

什么是 Text-To-4D?
Text-To-4D,也被称为 MAV3D(Make-A-Video3D),可以根据简单的文本描述生成三维动态场景。它利用一种为确保场景外观、一致性密度和运动优化的4D动态神经辐射场(NeRF),结合文本到视频的扩散模型实现。这使得创建可以从任何摄像机角度观看的动态视频成为可能,并能够集成到各种3D环境中。
不同于传统的3D生成方法,MAV3D不需要任何3D或4D的训练数据。它依赖于仅在文本-图像对和未标记视频上训练的文字到视频模型,使没有专门数据集的用户也能使用。这一方法为希望通过文本提示生成沉浸式3D动态内容的创作者、开发者和研究人员开启了新的可能性。
该工具面向广泛的用户群体,包括游戏开发者、动画师和虚拟现实内容创作人员,帮助他们无需手动建模或动画即可快速生成动态图景。它结合了文本驱动的生成与3D动态场景输出,具有独特的价值,可用于交互式应用或视觉叙事。
从技术上讲,该方法将4D NeRF与基于扩散的Text-to-Video模型集成,确保运动和外观在时间和空间上的一致性,从而生成平滑、逼真的动态场景,用户可以从多个角度进行探索。系统在之前的内部基础上取得了改进,能够根据文本输入生成更高质量、更连贯的3D视频。
整体而言,Text-To-4D作为首个能从文本生成完全动态3D场景的方法,弥补了文本视频生成与3D场景合成之间的差距,提供了一种灵活且创新的解决方案,用于创建沉浸式内容,无需复杂的3D数据或手动画面。
Neuralangelo Research Reconstructs 3D Scenes | NVIDIA 赞同数
Text-To-4D 赞同数
Neuralangelo Research Reconstructs 3D Scenes | NVIDIA 顶级功能
🎥 将2D视频剪辑转换为详细的3D模型,便于使用
🏛️ 高精度捕捉复杂纹理,如玻璃和大理石
🖼️ 支持重建小型物体和大型场景
📱 兼容智能手机拍摄的素材,简化捕捉过程
💻 开源代码可在GitHub获取,方便开发者使用
Text-To-4D 顶级功能
🎥 从文本提示生成动态3D视频,轻松创作内容
🌐 可从任意摄像角度查看生成的场景,自由探索环境
🛠️ 无需3D或4D训练数据,简化生成过程
⚙️ 结合4D神经辐射场和扩散模型,实现流畅运动
🔗 输出可集成到各种3D环境和应用中
Neuralangelo Research Reconstructs 3D Scenes | NVIDIA 类别
- 3D Generation
Text-To-4D 类别
- 3D Generation
Neuralangelo Research Reconstructs 3D Scenes | NVIDIA 定价类型
- Freemium
Text-To-4D 定价类型
- Free