Deep Voice 3 vs Unreal Speech
When comparing Deep Voice 3 vs Unreal Speech, which AI Text to Speech (TTS) tool shines brighter? We look at pricing, alternatives, upvotes, features, reviews, and more.
Between Deep Voice 3 and Unreal Speech, which one is superior?
When we put Deep Voice 3 and Unreal Speech side by side, both being AI-powered text to speech (tts) tools, Unreal Speech is the clear winner in terms of upvotes. Unreal Speech has been upvoted 9 times by aitools.fyi users, and Deep Voice 3 has been upvoted 6 times.
Want to flip the script? Upvote your favorite tool and change the game!
Deep Voice 3

What is Deep Voice 3?
Deep Voice 3 is an open source text-to-speech system that uses a fully convolutional neural network to convert text into natural-sounding speech. It supports both single-speaker and multi-speaker models, allowing it to generate speech in various voices and accents. The system is designed to scale efficiently, handling large datasets and training quickly compared to traditional TTS models.
The architecture includes an encoder that processes text inputs, an attention-based decoder that predicts mel-scale spectrograms, and a converter network that generates vocoder parameters for waveform synthesis. This design helps produce clear and natural speech with fewer mispronunciations. Deep Voice 3 also supports training on phoneme, character, or mixed inputs, which improves pronunciation accuracy.
Recent implementations have demonstrated the model's ability to synthesize speech from multiple speakers with distinct accents and ages, showcasing its versatility. Audio samples from various English accents, including Southern England and Scottish, highlight its adaptability to different speech styles.
Deep Voice 3 is suitable for developers and researchers interested in building scalable, high-quality TTS applications. Its open source nature allows customization and experimentation with different model configurations and datasets.
While the core technology remains consistent with the original design, ongoing community efforts focus on improving training efficiency and expanding multi-speaker capabilities. The system's modular structure facilitates integration with other speech processing tools and vocoders.
Overall, Deep Voice 3 offers a balance of speed, scalability, and speech quality, making it a valuable resource for those working on speech synthesis projects that require flexibility across voices and languages.
For detailed technical insights and implementation guidance, the original research paper and open source repositories provide comprehensive resources.
Unreal Speech
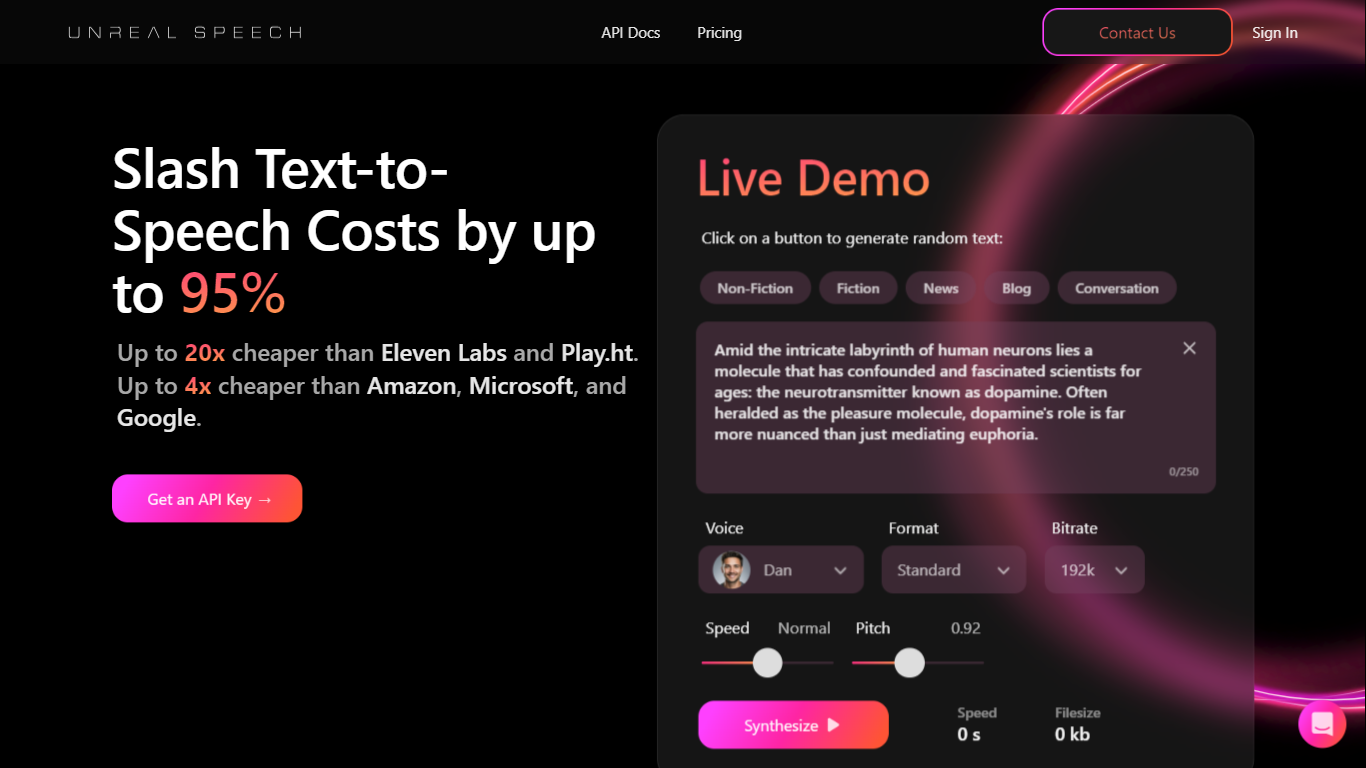
What is Unreal Speech?
Unreal Speech is a production-ready text-to-speech API built on the open-source Kokoro TTS engine. It gives developers and businesses natural speech synthesis at a fraction of the cost of ElevenLabs, Amazon Polly, Google Cloud, and Microsoft Azure. The API streams audio in about 300 milliseconds and supports long-form jobs up to 10 hours per request.
Kokoro runs on an 82-million-parameter decoder-only model that blends ideas from StyleTTS 2 and iSTFTNet. You get 48 voices across eight languages, including US and UK English, Mandarin, Hindi, Spanish, Portuguese, Japanese, French, and Italian. Per-word timestamps let apps highlight text in sync with playback, which helps with accessibility, karaoke-style UIs, and interactive readers.
The REST API exposes four endpoints: /stream for sub-second synthesis of up to 1,000 characters, /speech for up to 3,000 characters with timestamp URLs, /synthesisTasks for async jobs up to 500,000 characters, and a websocket /streamWithTimestamps route for live audio plus word timing. SDKs ship for Python, Node.js, and React Native, with sample code on the homepage.
Kokoro TTS Studio on unrealspeech.com offers a free browser demo to test voices before signing up. Paid plans remove attribution requirements for commercial audio. Enterprise customers on the platform process billions of characters monthly with 99.9% uptime.
Deep Voice 3 Upvotes
Unreal Speech Upvotes
Deep Voice 3 Top Features
🎤 Multi-speaker support with varied accents and ages for diverse voices
⚡ Fast training speeds enabling quicker model development
🧩 Flexible input options using phonemes, characters, or both for better pronunciation
🔊 Generates mel-scale spectrograms for high-quality audio synthesis
🔧 Open source codebase allowing customization and integration
Unreal Speech Top Features
Streams up to 1,000 characters in about 300ms via /stream
Async synthesis tasks handle up to 500,000 characters per request
Per-word timestamps sync text highlighting with audio output
48 voices across eight languages with speed and pitch controls
Websocket /streamWithTimestamps delivers live audio plus timing data
Python, Node.js, and React Native SDKs ship with code samples
Single synthesis jobs can produce up to 10 hours of audio
Deep Voice 3 Category
- Text to Speech (TTS)
Unreal Speech Category
- Text to Speech (TTS)
Deep Voice 3 Pricing Type
- Freemium
Unreal Speech Pricing Type
- Freemium