
Last updated 06-29-2026
Category:
Reviews:
Join thousands of AI enthusiasts in the World of AI!
Unreal Speech
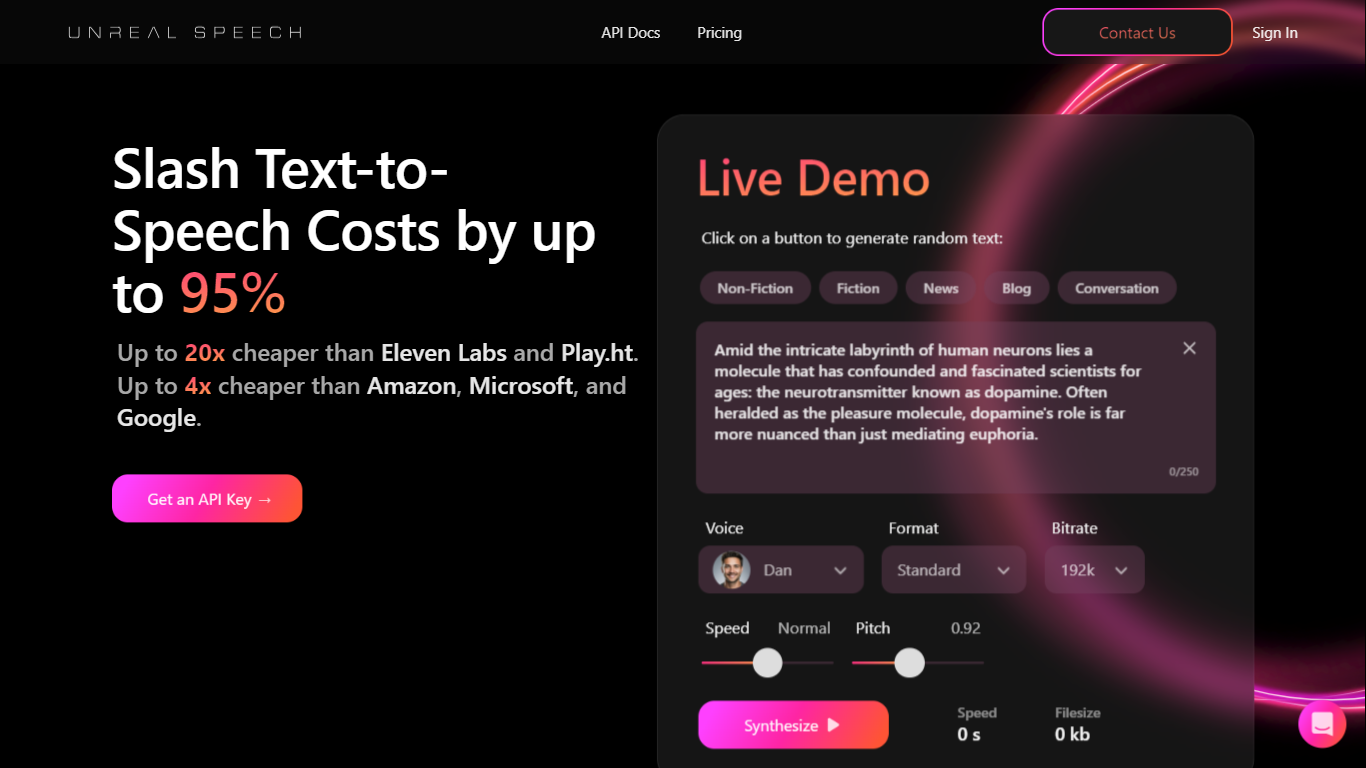
Unreal Speech is a production-ready text-to-speech API built on the open-source Kokoro TTS engine. It gives developers and businesses natural speech synthesis at a fraction of the cost of ElevenLabs, Amazon Polly, Google Cloud, and Microsoft Azure. The API streams audio in about 300 milliseconds and supports long-form jobs up to 10 hours per request.
Kokoro runs on an 82-million-parameter decoder-only model that blends ideas from StyleTTS 2 and iSTFTNet. You get 48 voices across eight languages, including US and UK English, Mandarin, Hindi, Spanish, Portuguese, Japanese, French, and Italian. Per-word timestamps let apps highlight text in sync with playback, which helps with accessibility, karaoke-style UIs, and interactive readers.
The REST API exposes four endpoints: /stream for sub-second synthesis of up to 1,000 characters, /speech for up to 3,000 characters with timestamp URLs, /synthesisTasks for async jobs up to 500,000 characters, and a websocket /streamWithTimestamps route for live audio plus word timing. SDKs ship for Python, Node.js, and React Native, with sample code on the homepage.
Kokoro TTS Studio on unrealspeech.com offers a free browser demo to test voices before signing up. Paid plans remove attribution requirements for commercial audio. Enterprise customers on the platform process billions of characters monthly with 99.9% uptime.
Streams up to 1,000 characters in about 300ms via /stream
Async synthesis tasks handle up to 500,000 characters per request
Per-word timestamps sync text highlighting with audio output
48 voices across eight languages with speed and pitch controls
Websocket /streamWithTimestamps delivers live audio plus timing data
Python, Node.js, and React Native SDKs ship with code samples
Single synthesis jobs can produce up to 10 hours of audio
Published pricing runs about 11x cheaper than ElevenLabs at comparable tiers
Four API endpoints cover real-time streaming and long async synthesis jobs
Per-word timestamps support synced highlighting and accessibility features
Free tier includes 250,000 characters with full voice and language access
Kokoro TTS engine is open source and can also be self-hosted locally
Voice cloning is not available on the hosted API yet
Free plan requires attributing Unreal Speech in published commercial audio
Studio browser demo limits input to 500 characters per generation
What languages and voices does Unreal Speech support?
Unreal Speech offers 48 voices across eight languages: US English, UK English, Mandarin Chinese, Hindi, Spanish, Portuguese, Japanese, French, and Italian. You can pick voices, adjust speed and pitch, and choose output formats including MP3 and PCM.
Does Unreal Speech have a free plan?
Yes. Unreal Speech includes a free tier with 250,000 characters per month, roughly six hours of audio. You get access to all voices and languages. Free-plan audio used commercially must include a link to unrealspeech.com in the description.
How fast can Unreal Speech generate audio?
Unreal Speech streams audio in about 300 milliseconds through the /stream endpoint for up to 1,000 characters. Longer jobs via /speech or /synthesisTasks take roughly one second per 700 to 800 characters depending on the endpoint.
Does Unreal Speech support voice cloning?
Unreal Speech does not offer custom voice cloning on the API yet. The team states that voice cloning is in development. The Kokoro open-source model can be fine-tuned locally for custom voices outside the hosted API.
What happens if I exceed my monthly character limit?
Unreal Speech bills overage usage daily at your plan rate: Basic at $16 per 1 million characters, Plus at $12, Pro at $10, and Enterprise at $8. Unused characters on paid plans roll over to the next billing cycle. Free-plan characters reset on the first of each month.
Can I use Unreal Speech audio commercially?
Yes. Unreal Speech allows commercial use of generated audio. Free-plan users must attribute Unreal Speech with a link to unrealspeech.com in published content. Paid subscribers do not need attribution.
What API endpoints does Unreal Speech provide?
Unreal Speech exposes /stream for instant audio up to 1,000 characters, /speech for up to 3,000 characters with timestamp URLs, /synthesisTasks for async jobs up to 500,000 characters, and /streamWithTimestamps over websocket for real-time audio with word-level timing.