
Last updated 04-26-2025
Category:
Reviews:
Join thousands of AI enthusiasts in the World of AI!
NVLM LLMs
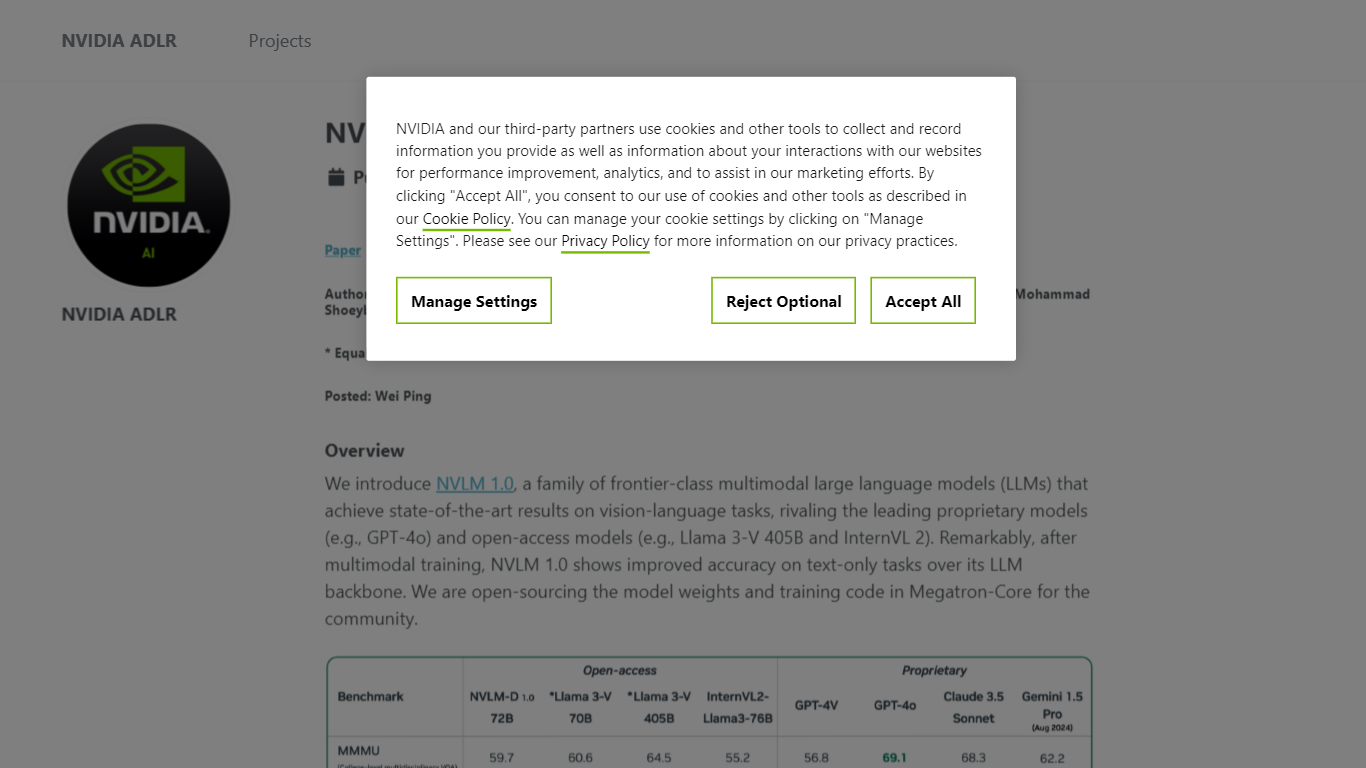
NVLM 1.0 is a family of frontier-class multimodal large language models (LLMs) developed by NVIDIA ADLR, designed to excel in vision-language tasks. These models achieve state-of-the-art results, competing with both proprietary models like GPT-4o and open-access models such as Llama 3-V 405B and InternVL 2. A standout feature of NVLM 1.0 is its ability to improve text-only performance after undergoing multimodal training, showcasing its versatility and effectiveness in various applications.
The target audience for NVLM 1.0 includes researchers, developers, and organizations looking to leverage advanced AI capabilities for tasks that require understanding and generating both text and visual content. By open-sourcing the model weights and training code in Megatron-Core, NVIDIA aims to foster community engagement and collaboration, allowing users to build upon their work and integrate these models into their own projects.
One of the unique value propositions of NVLM 1.0 is its demonstrated ability to outperform or match leading models across key benchmarks, including MathVista, OCRBench, ChartQA, and DocVQA. This performance is particularly notable in the context of text-only tasks, where NVLM 1.0 shows significant improvements over its LLM backbone, making it a compelling choice for users who require high accuracy in both multimodal and text-only scenarios.
Key differentiators of NVLM 1.0 include its strong instruction-following capabilities and its ability to generate high-quality, detailed descriptions based on provided images. The model's versatility is further highlighted by its proficiency in various multimodal tasks, such as OCR, reasoning, localization, and coding. This makes NVLM 1.0 suitable for a wide range of applications, from academic research to practical implementations in industries like education and technology.
In terms of technical implementation, NVLM 1.0 utilizes advanced training techniques to enhance its performance on both vision-language and text-only tasks. The model's architecture allows it to effectively integrate visual information with textual data, enabling it to perform complex reasoning and generate coherent outputs. This technical foundation, combined with its open-source availability, positions NVLM 1.0 as a leading solution in the field of multimodal AI.
State-of-the-art performance on vision-language tasks, helping users achieve high accuracy in complex applications.
Improved text-only performance after multimodal training, ensuring versatility for users who need reliable outputs in various formats.
Open-source model weights and training code, allowing developers to customize and build upon the existing framework.
Strong instruction-following capabilities, enabling the model to generate responses that align closely with user prompts.
Versatile capabilities in OCR, reasoning, localization, and coding, making it suitable for a wide range of practical applications.
1) What is NVLM 1.0?
NVLM 1.0 is a family of multimodal large language models developed by NVIDIA that excel in vision-language tasks.
2) Who can use NVLM 1.0?
Researchers, developers, and organizations looking to utilize advanced AI for text and visual content can use NVLM 1.0.
3) How does NVLM 1.0 improve text-only performance?
After multimodal training, NVLM 1.0 shows improved accuracy on text-only tasks compared to its LLM backbone.
4) Is NVLM 1.0 open-source?
Yes, NVLM 1.0 provides open-source model weights and training code in Megatron-Core for community use.
5) What are the key benchmarks NVLM 1.0 excels in?
NVLM 1.0 achieves high performance in benchmarks like MathVista, OCRBench, ChartQA, and DocVQA.
6) What unique capabilities does NVLM 1.0 have?
NVLM 1.0 can perform OCR, reasoning, localization, and coding, making it versatile for various tasks.
7) How does NVLM 1.0 compare to other models?
NVLM 1.0 competes with leading models like GPT-4o and Llama 3-V, showing comparable or superior performance.